2022秋季学期 计算机组成原理 期末复习笔记
计组复习笔记
12 Instructions
PC 需要执行的指令,下一条指令
程序最小单元:指令,也是计算机硬件执行程序的最小单位
全部指令构成指令系统
层次
软件系统:高级、汇编、OS、指令系统
硬件系统:指令系统、微体系结构、数字逻辑
指令系统是软硬件接口
功能分类
运算、传输、控制、IO、其他
操作码和操作数地址,指令字:二进制表示
指令字长:每条指令是x倍机器字长
机器字长:计算机能处理的二进制数据位
可变长的指令字结构和扩展操作码…
寻址
指令中的地址叫形式地址,使用形式地址信息计算or读到的数值才是实际数据(或指令)的实际地址
Regor累加器编号 IO设备端口地址 储存器单元地址
性能评定
- 吞吐率:单位时间完成任务数量
- 响应时间:完成任务时间
- MIPS 每秒几百万条指令处理能力
- CPI 每条指令几个周期
- CPUTime?
- CPUclock?
- 测试程序
CR
Cisc 可变长
Risc 等长指令(除了压缩instr) 并行好编译效率高
VLIW 超长指令字 组合简短等长的精简指令成超长指令,每次运行一个超长而并发执行多个短指令
最好让reg位置保持不变位置相同

R
R的opcode固定 规整计算结果到rd,PC增加
I
imm12符号扩展32位,-2048 2047
移位中imm只有后五位有效位shamt,前七位为0
逻辑移动补0,算数右移补符号位
JALR 符号扩展12到32,把pc+4存到rd,跳rs1+-imml31:1,0
,相当于先扩展相加后把最低位置0.
跳转范围rs1+-4KB,结合AUIPC可以任意跳了
LB LW 符号扩展后的imml+rs1的位置取字或字节
S
rs2存到rs1+符号扩展imm上,此处imm被打散
B
比较rs1 rs2,符号扩展~imm12,0其实是imm12:0 ,与PC相加,pc±2^12=4K(B)
-4096 4094的2B对齐偏移
如果超过了可以b的条件反转,然后bnxt,jjump
J
打散的imm20因为其实是20:1后面默认0位为0,JAL 符号扩展,存pc+4到rd然后和pc相加低位置0后跳+-1MB
U imm除了U之外都要符号扩展
不打散的imm20,lui直接装
auipc:装入高20位后加上pc
MMIO
通过把IO映射到内存单元,对特殊地址读写就是读写外设。通过外设寄存器和主机交互,表现为内存单元或者端口上的数据读写单元
13 数字逻辑
解码器|译码器 2-4,3-8… 选择器,控制信号和数据与后接入或门
比较器:或许是异或+与门
3LUT查找表,实现任何3位逻辑函数,就是根据abc8种情况查找定制的输出
摩尔状态机:输出之和现在状态有关,延迟一拍
米利状态机:输出和现态和输入都有关,快,异步反馈问题
同步电路:全局时钟,有利于静态时序分析,强耦合。不利于面积和低功耗优化,时钟偏斜(和时钟距离不同)
异步电路:多个时钟,不同源or同源不同相,难以静态时序分析,但是更灵活,功耗低
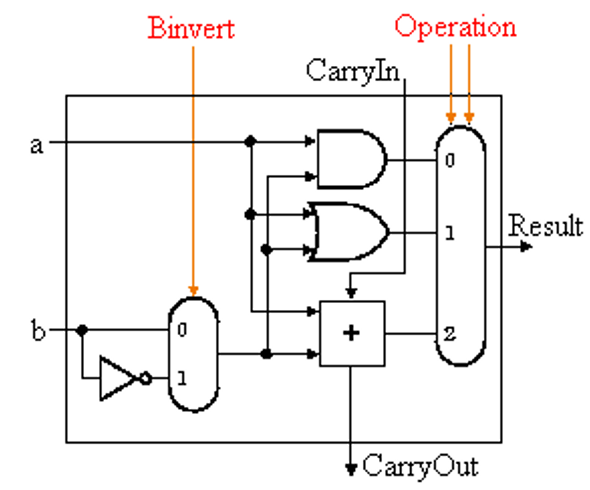
14 ALU
寄存器堆——ALU——回到寄存器堆
全加器
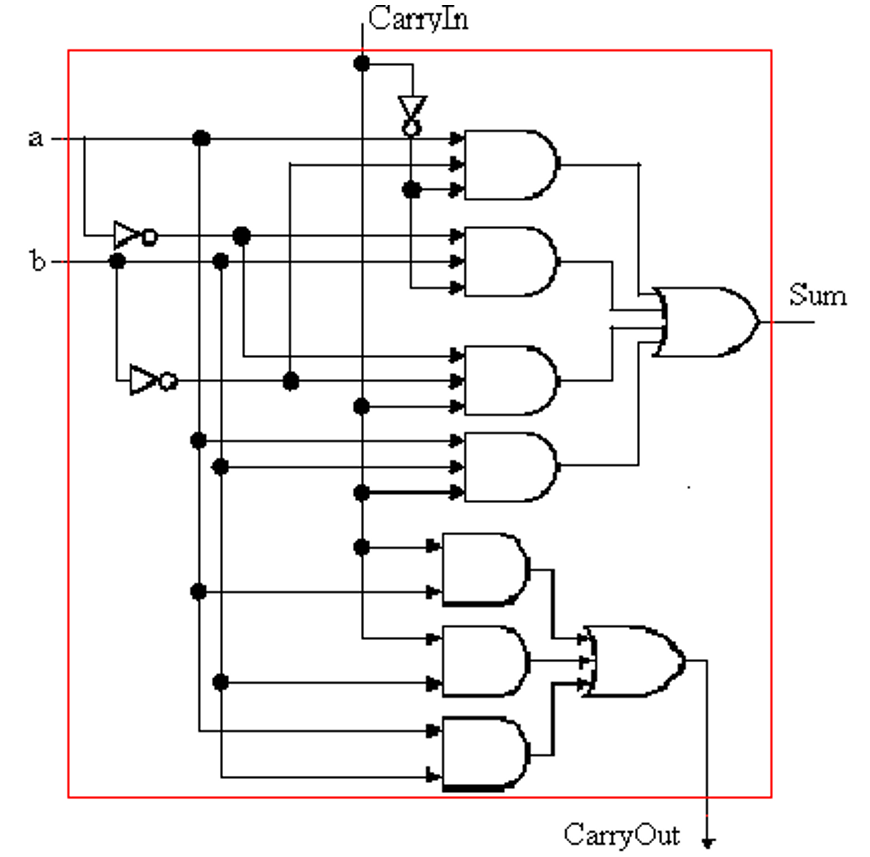
1位ALU
4位ALU?真值表组合逻辑or串4个1位
超前进位?特殊进位电路来同时得到计算结果和进位C1234
标志位:ZF SF最高位 OV=¬F1*¬F2*S+F1*F2*¬S溢出@@
补码减法
b的补码取反加一为-b直接加即可
原码乘法
高精度(竖式),即移位加。
维护部分积,先从乘数最高位开始,1就加0不动。处理完一位就左移部分积直到处理完乘数
或者:
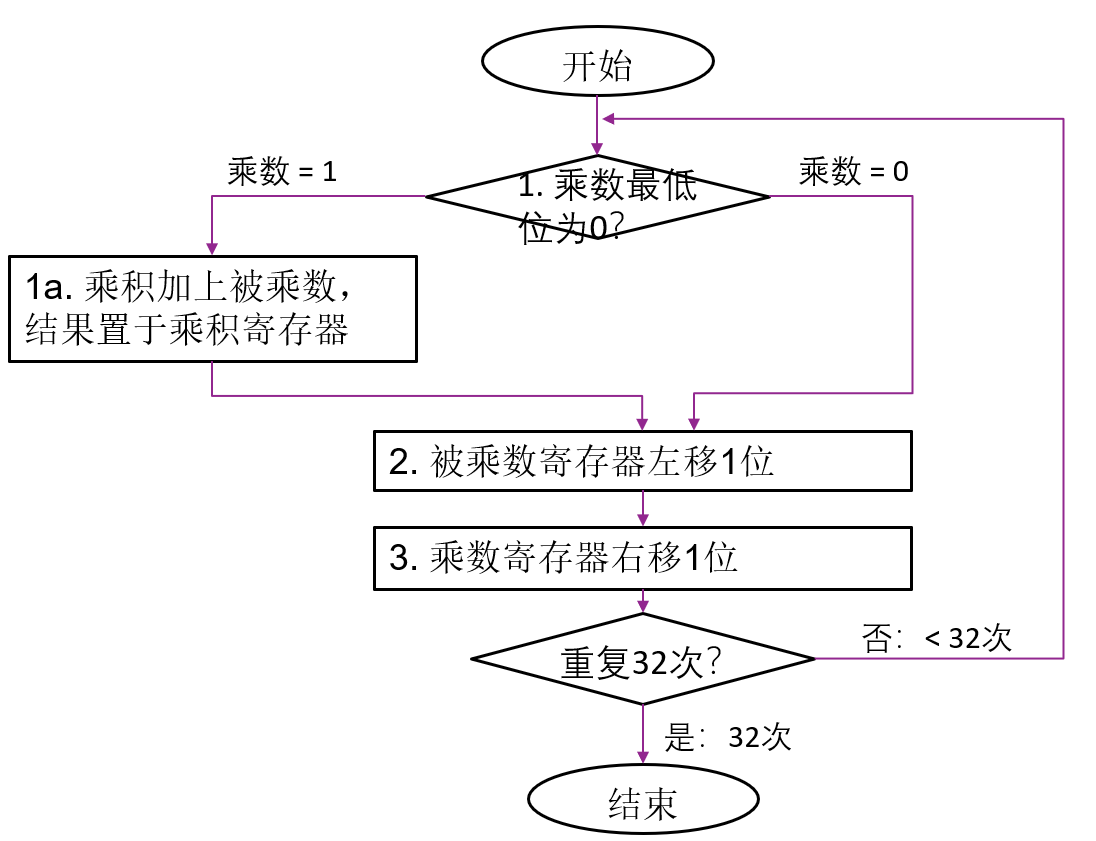
很可能溢出,怎么办?
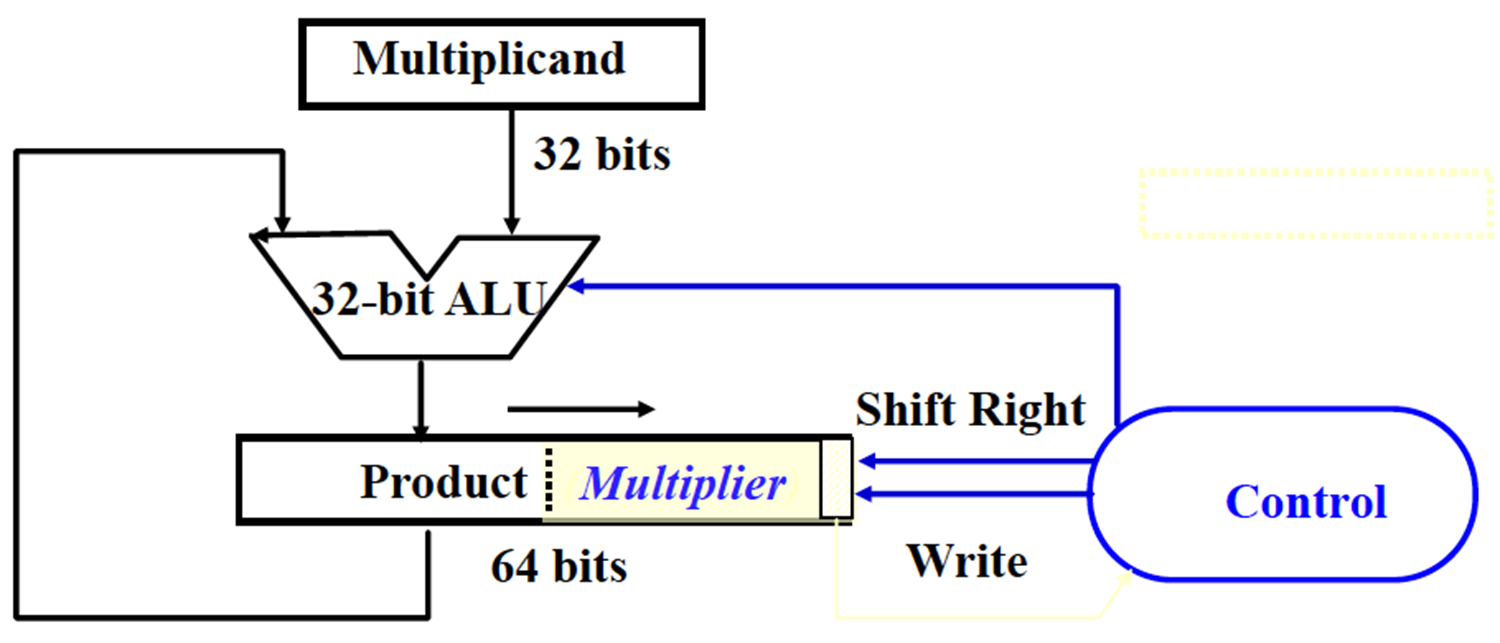
1直接实现:64位被乘数,64位ALU,64位部分积,32位乘数… 浪费空间,每次加法只有一半生效
2 32位被乘数和ALU,64位部分积 其实64位被乘数(不断左移)就是为了对应落在部分积的正确位置。换思路让部分积右移,即alu只往部分积高32位加,加后右移即可
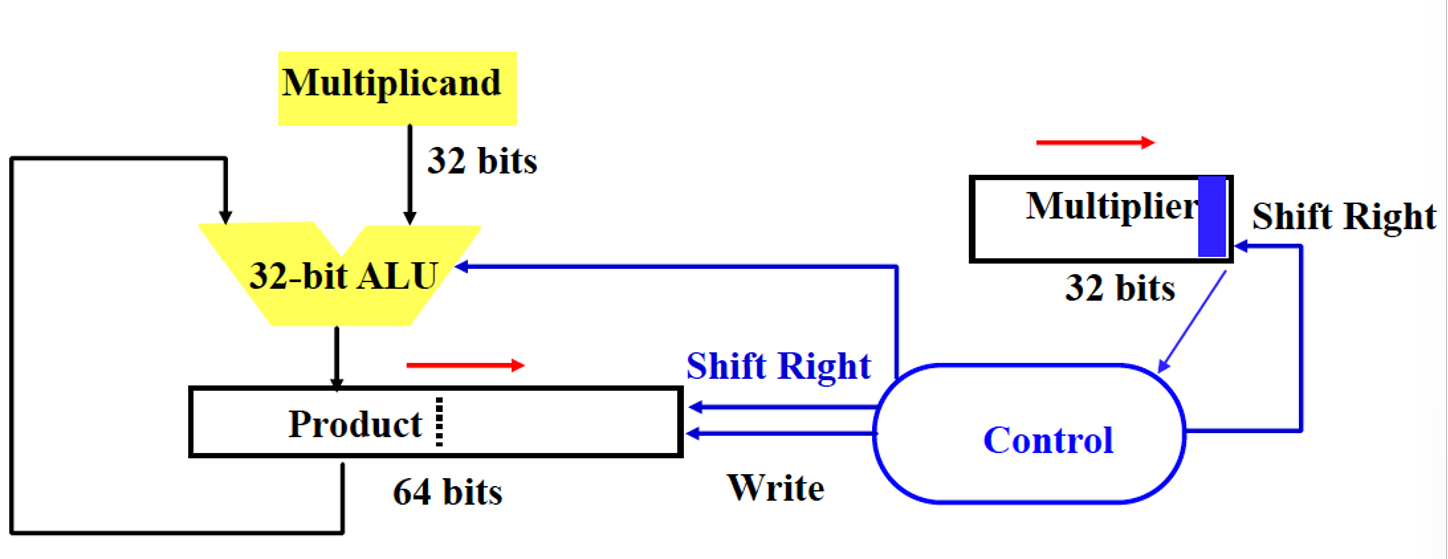
发现部分积在不断右移,而乘数右移之后左边没用,故合并..
补码乘法?
1 补码换原码绝对值,乘法,单独算符号位
2 布斯算法 原理推导
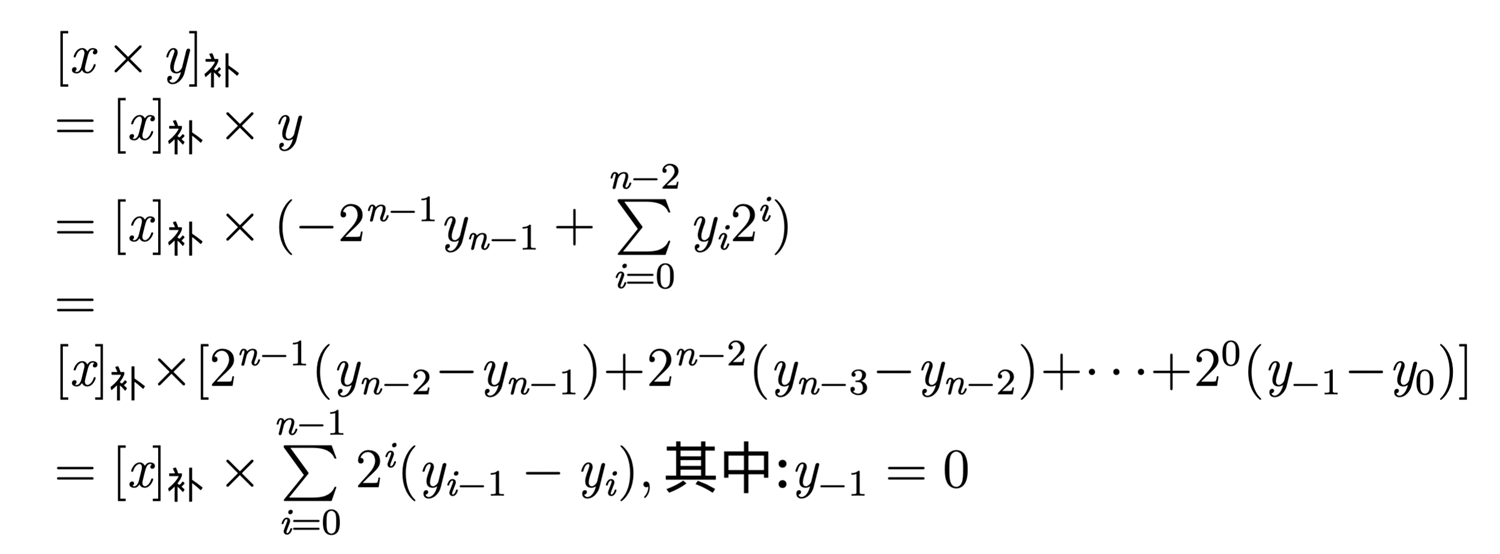
其实就是在标准的部分积-乘数寄存器后追加一位初始0,然后开始看最后一位和附加位。10减01加,右移固定长度后计算完毕(把所有除数出去就完事)
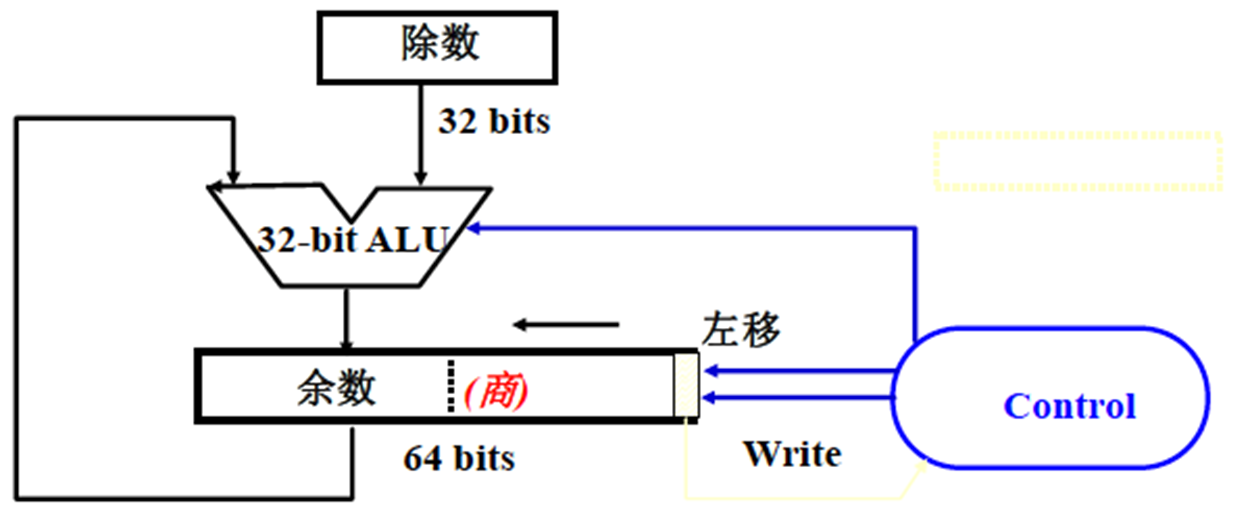
除法
异或符号,绝对值做除法
恢复余数法:经典的竖式,被除数减除数后,大于等于零商1,移位。小于零则商0,恢复余数后移位。从来不用。
一般用负余数向下求加减交替法 原理证明:

操作方法?
原码:首轮尝试 -Y,后面看正负。正商1-Y 负商0加Y。最后修正符号。记得余数要乘上2^-n的系数
补码:首轮根据符号同异。同减,后与除数同号商1减 异号商0加。
如果最后余数为负轮次,加Y修正之
最后
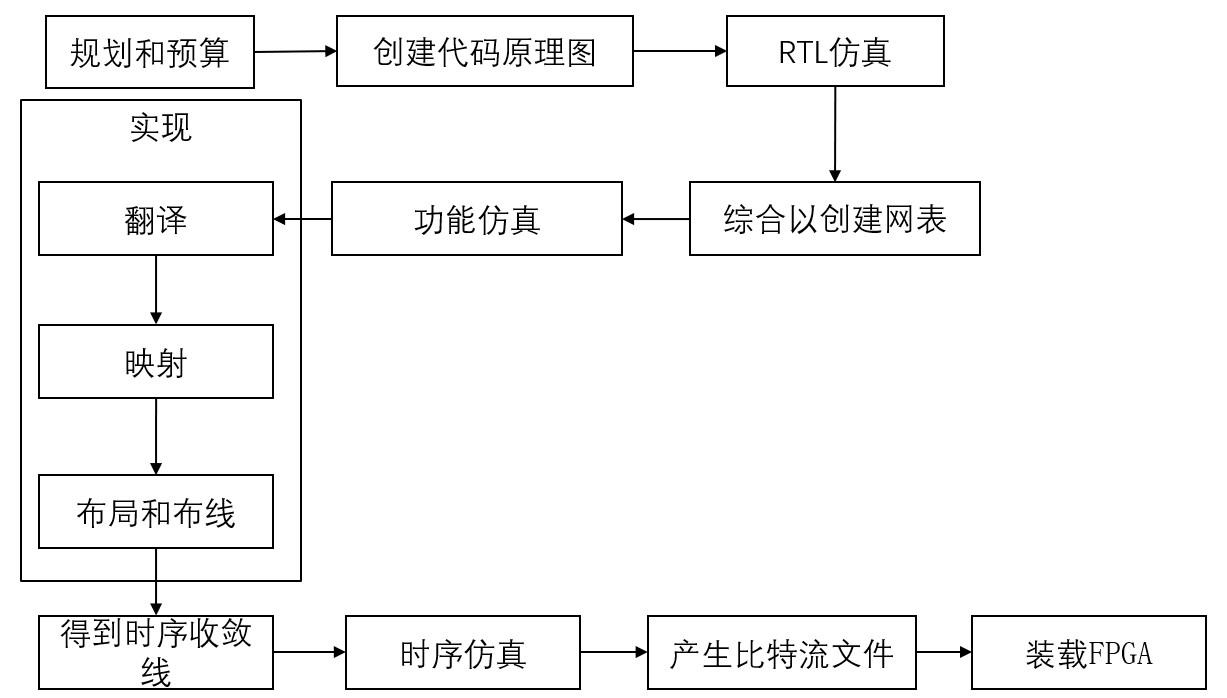
15 实验预备和Verilog
FPGA 现场可编程门阵列,以LUT 触发器等为基本单元
LUT本质就是RAM,计算所有结果之后按地址查表输出
面积 和 速度的平衡和互换
现在的FPGA都是为同步电路设计优化的,但从IC设计看同步更加耗资源,没有毛刺信号稳定。
综合后仿真可以标注标准延时文件,估计门延时等等;时序仿真更靠后
Verilog
- 门级描述(结构)和行为描述
- Z不是0不是1,如果进与门则有0为0,其余为X
- 仿真时#x表示延时xns 1ns/1ps下 代码时间单位/仿真粒度
- 异步复位:采样独立于时钟,优先权最高,但对毛刺敏感有亚稳态问题
- 同步复位:相对于时钟,应该有足够长激活时间以在时钟边缘采样到rst
16数据表示和纠错
逻辑数据 01
字符数据
ascii 128 Unicode 16b保留6400个码本地化使用
UTF8变长编码,首字节确定字符长度,开头为几个1和一个0代表字节数。0为单字节,几个1加0是几个字节。后面字节都以10开头,方便自同步。
点阵字体,通过10来绘制汉字;矢量字体,通过平滑曲线连接关键点,填充闭合空间来显示字符
数值数据
定点数与浮点数
原 反 补
正数相同
0有两个原码和反码
反码为原码取反,补码为反码加一
只有一个负数的原码和补码是相同的即1100 -4 = -8+4
浮点数
s exp frac: 1 3 4 or 1 8 23 or 1 11 52 bias = 2^(exp-1) -1
bias:3 127 1023
特殊情况:
exp=0 不取-3仍-2,但是0.frac,有正负0
exp=全1且frac=0 表示无穷大,frac其他NAN
exp 非0且非全1: 规格化数 正常处理 1.frac exp-bias
浮点算数






特点:不可结合,相等比较只是近似的。比如for中i!=10的条件,递增0.1可能不会停止
检错纠错
奇偶校验
并行数据传输,k后加1位。使得k+1取1的位数为偶or为奇数
即奇校验的校验位为是否为偶数个1,or偶个1出错为1,
把校验位写前面?
全部异或——偶校验
码距2 少用一个维度的合法码可以使码距为2,可以得到检错码。
海明码
发现并改正一位错:2^r >= k+r+1, 全正确和k+r的某一位出错的情况
实用,也能发现两位错:r中一位来表示1位还是2位错,剩下来指示出错2^r-1 >=k+r
3-4海明码,垃圾。
在正常海明码后面加一个校验位P4为所有其他位的异或。
校验位和对应数据位异或应该全是0为无措,否则找为1的
全校验位为1则一位错,为0有两位错
21 控制器 指令系统
操作数
x操作数指令(x地址指令)
来源去向:寄存器堆、IO设备或接口的寄存器,主存单元
操作码扩展,可以用1占位用0开始,参考utf8的方案即1110后面是可变
也可以自己设计,从操作数最多的指令开始即可 从多地址到少地址
操作数类型和寻址
- 指令中包含imm
- 给出mem地址
- 寄存器寻址(reg中是实际数据)和间接寻址(寄存器中是内存地址)
- 变址寻址:变址寄存器值+偏移量
- 相对寻址:相对于PC和偏移量
- 间接寻址:指令给出**data 访存两次
- 基地址寻址:基地址专用寄存器如fp,+偏移量
- 堆栈寻址:处理sp,加减和读写fp
22 Riscv指令系统
算数与逻辑运算、移位操作、数据传送、IO、转移、子程序调用返回、堆栈、其他(条件码、中断、停机、nop、特权)
推荐不强制对齐,小端高对高,高——低
完整64位multi:mulh[[s]u] rdh, rs1, rs2; mul rdl, rs1, rs2 div rem
lw sw中addr+off需要按4B对齐
lb会符号扩展!half是2B指令2B对齐,如果u做0扩展
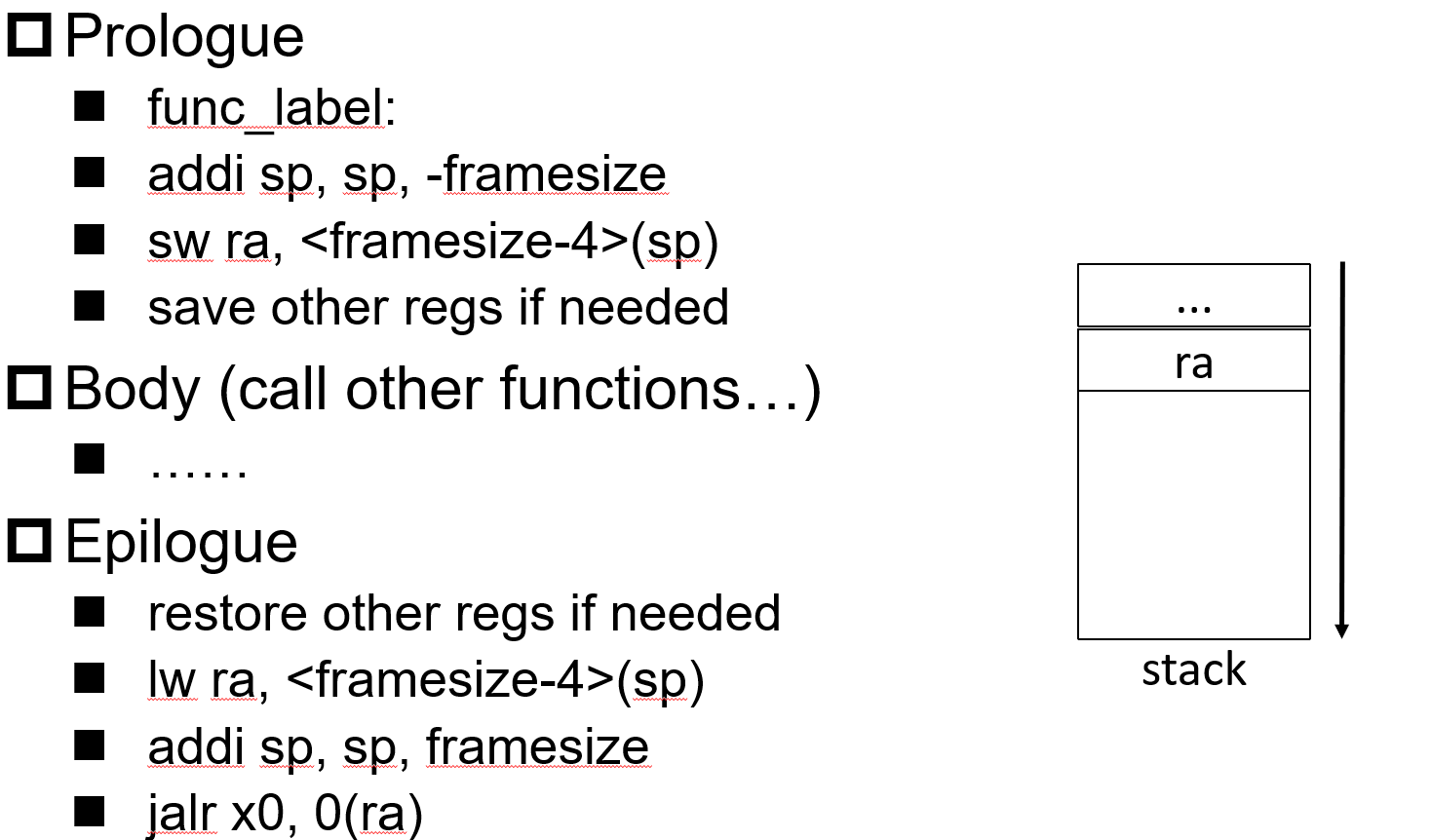
callee:sp fp\s0 s1-11,函数如果需要,则需要保存下原来值,最后再恢复
caller:ra,t0-t6,a0a1 a2-a7,被调用可以自由用,即func内需要的话随便用
23 指令格式和数据通路
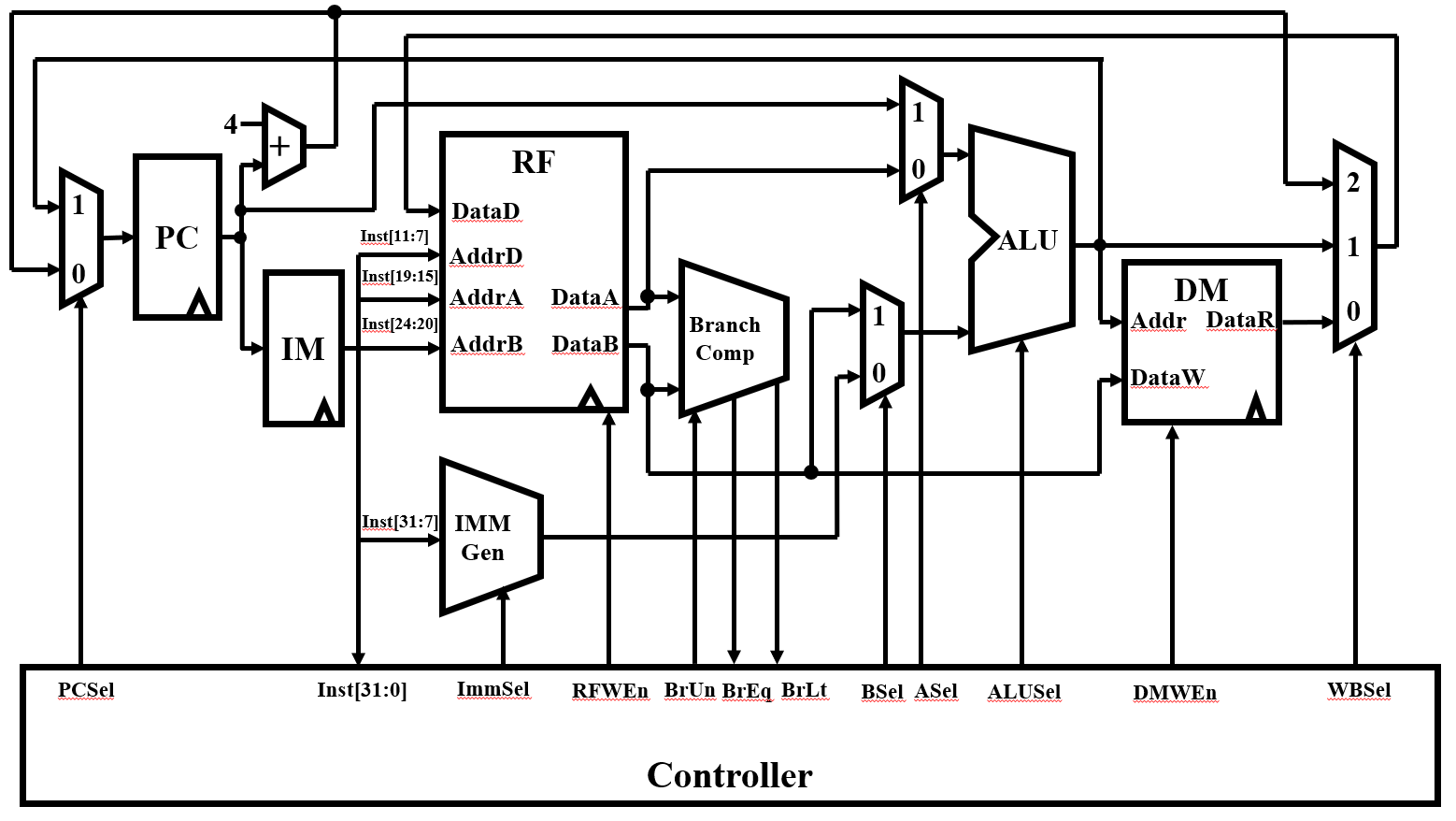
24 单周期cpu
指令周期 执行一条指令的时间,有cpi即每个指令需要几个cpu周期
cpu周期 clk时间,甚至可以再分为节拍
cpi=1的单周期,五个步骤挤在一个cpu周期内。各个控制信号在整个指令周期不变
古早技术,利用率低,不实用
考虑:数据通路、控制信号、执行时序
组成部件利用率不高,消耗在维持信号上
时钟周期满足执行时间最长的指令如load比store多wb,以load限制最长周期
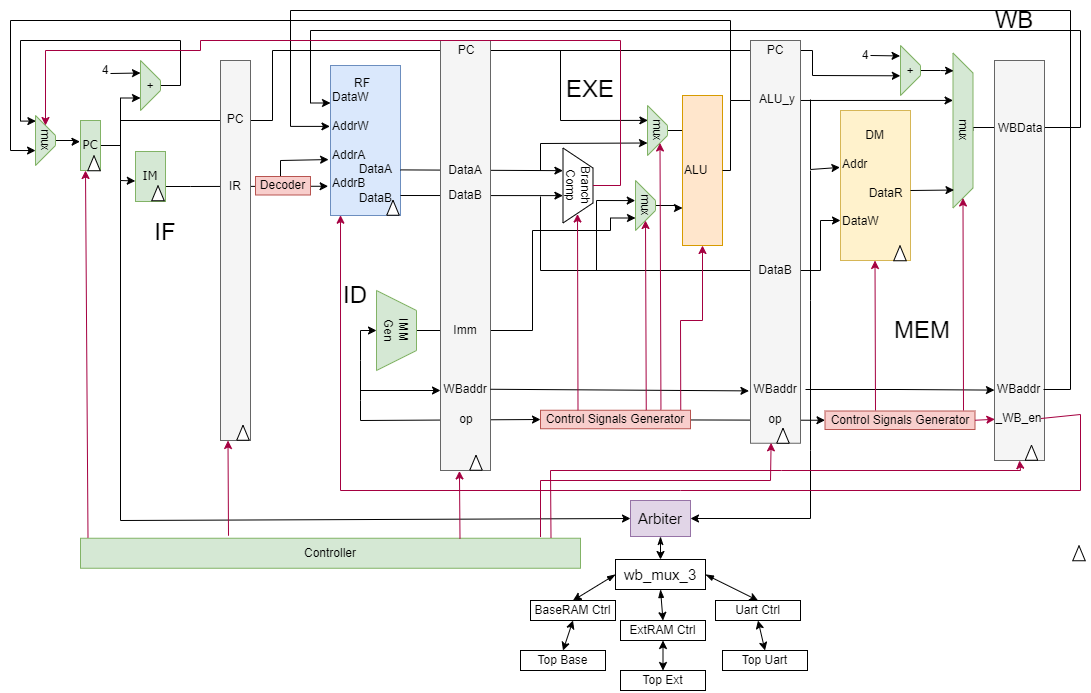
25 多周期cpu
指令占用自己的步骤数,每个步骤占一个周期,尽量限制单一部件,仅提供当前步骤的控制信号
需要:保存好下一步骤的值——引入寄存器
转到下一步骤——引入状态标记,使用状态机
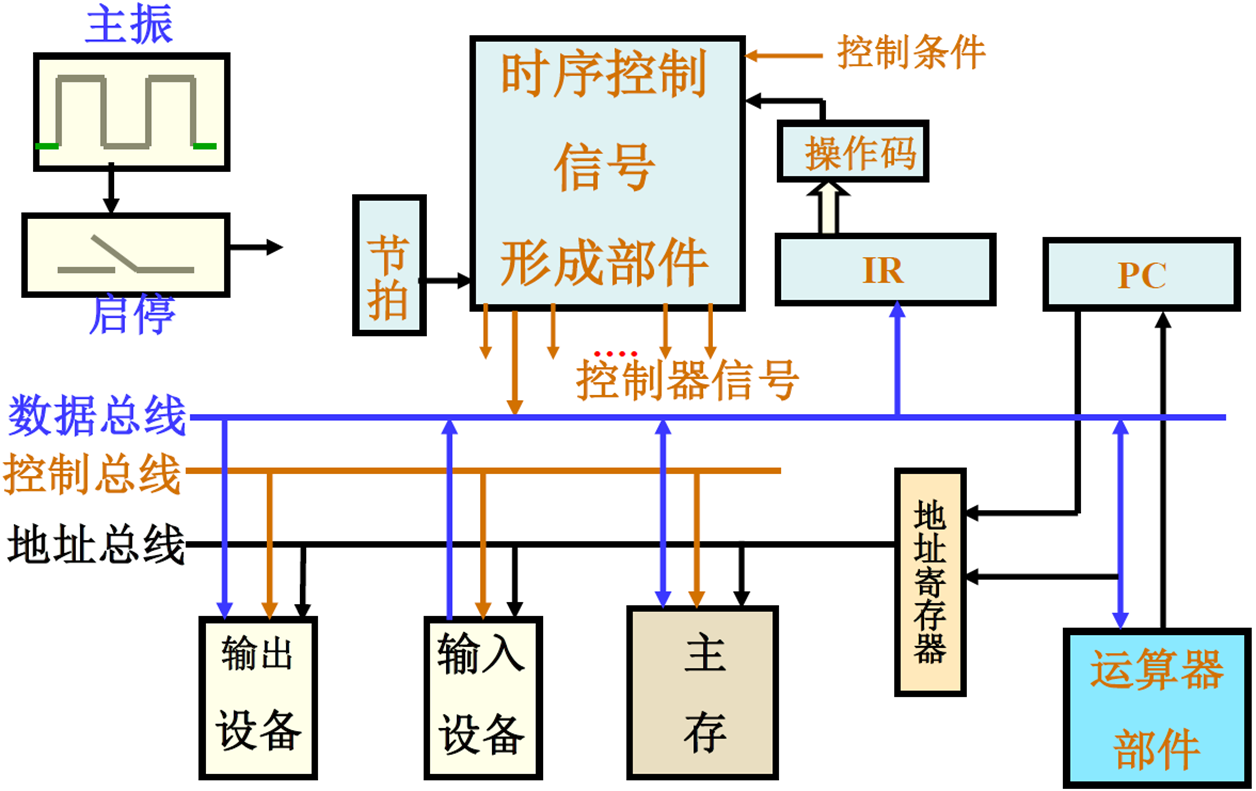
控制器组成
PC IR 指令执行步骤标记:每条指令的步骤和次序
控制信号产生:根据当前状态产生控制信号
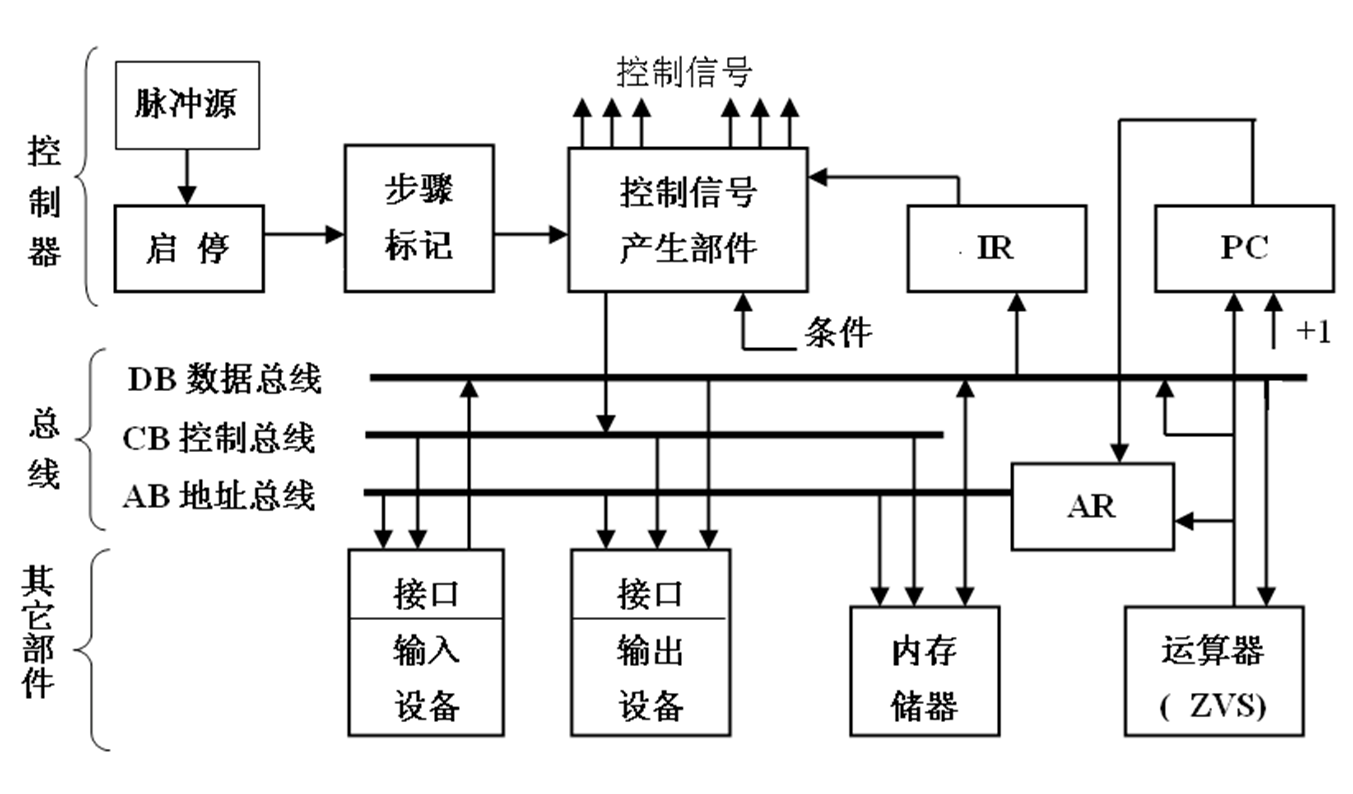
硬连线组合逻辑控制器 指令和执行步骤产生控制信号
PC IR 节拍发生Timer 控制信号产生部件,条件包括条件码等
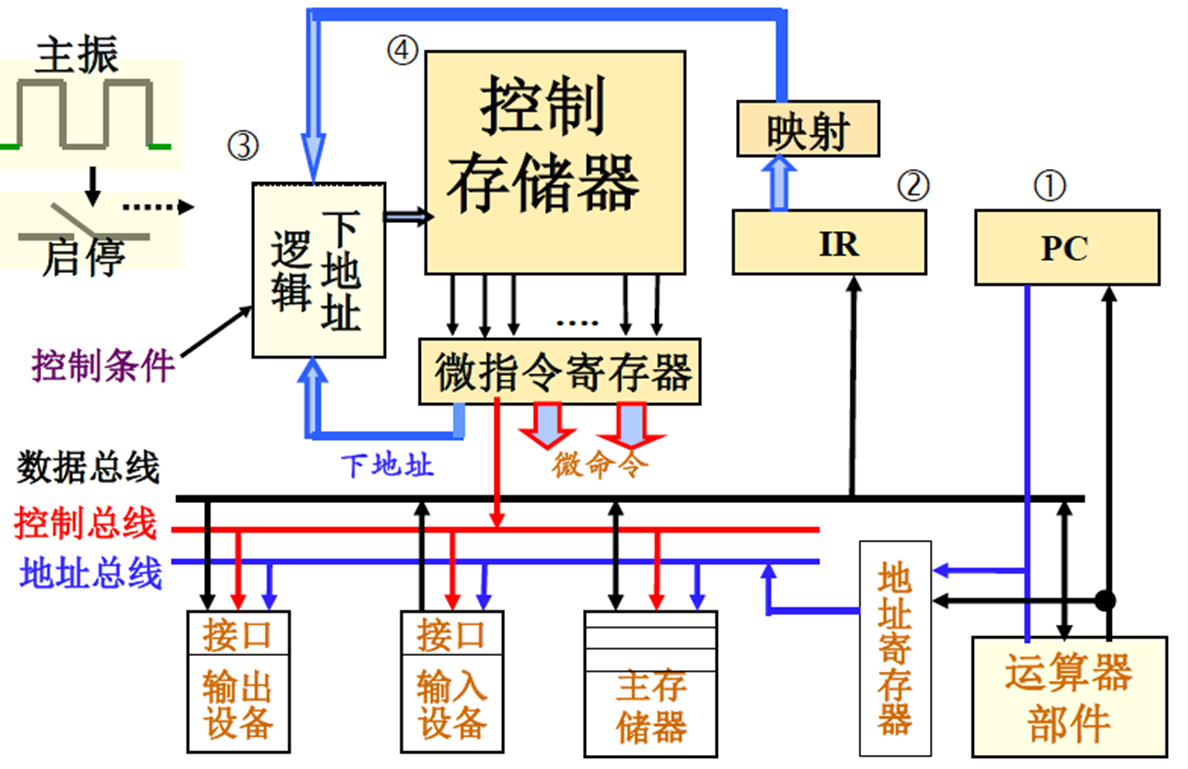
微程序 存储控制信号,依据步骤读出要用的组合
微地址访问读出,指令操作码得到首条微指令地址,然后微指令给出下一步骤地址
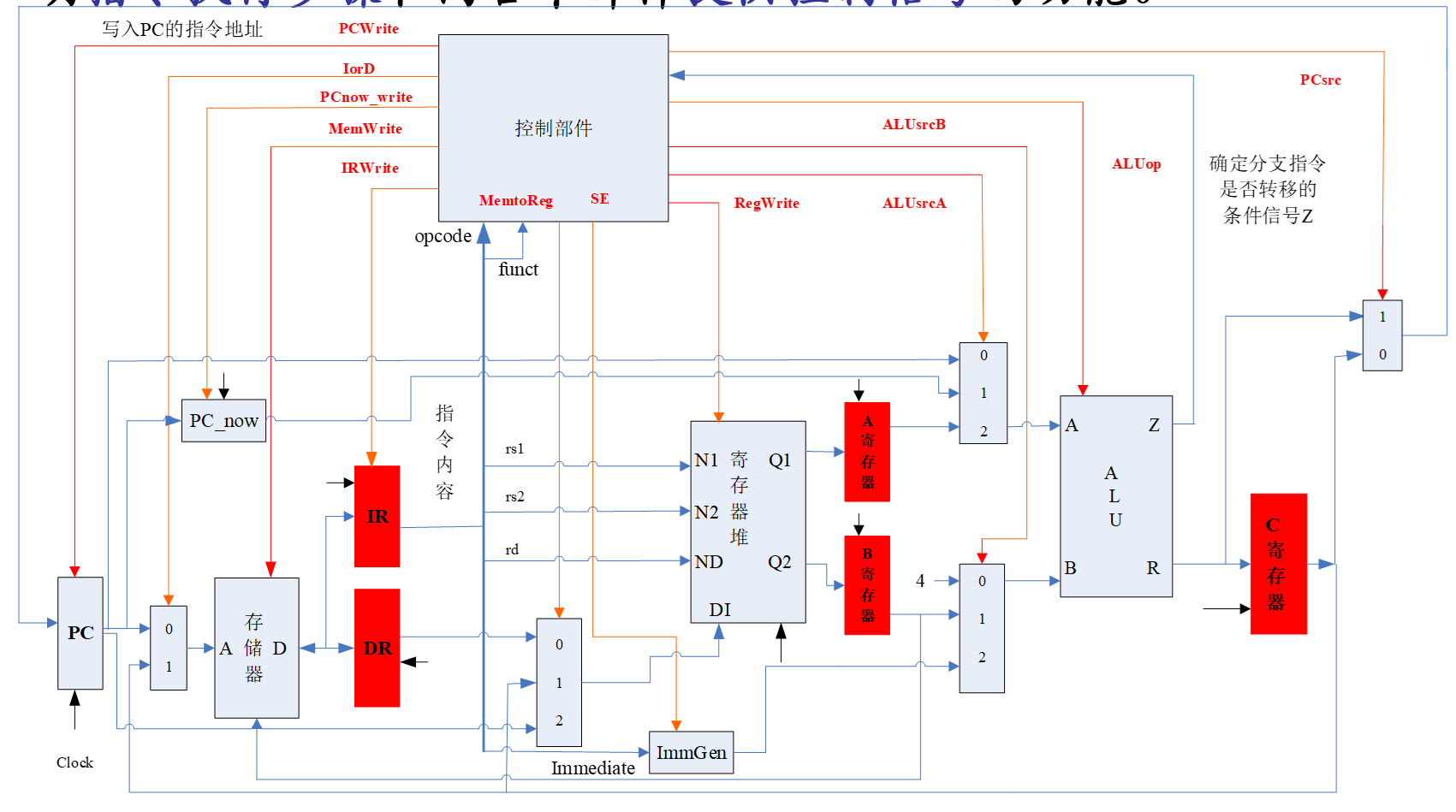
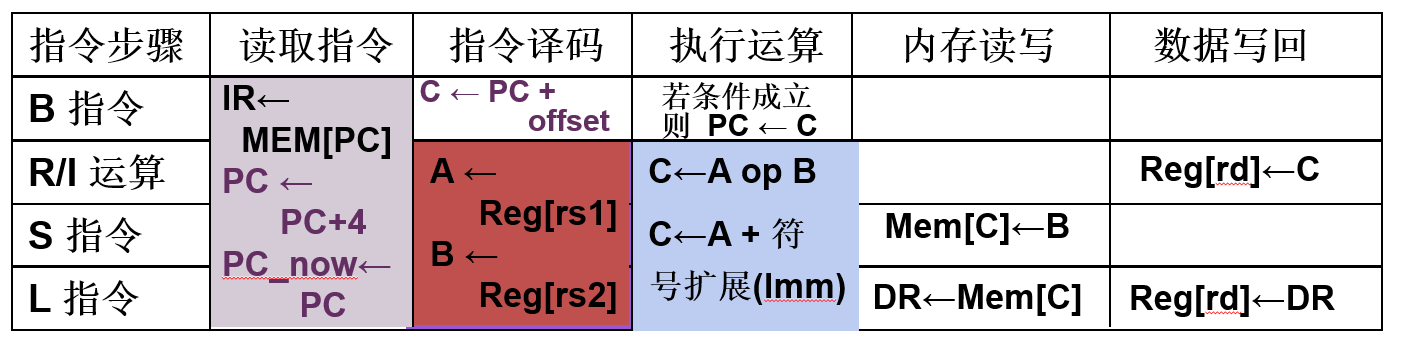
读指令 PC地址读到IR
load C addr 保存到DR
wb的wdata来自C DR或者PC
AB寄存器其实是mux后的alua和alub,C暂存最终ALU结构
A的来源:rs1 pc pc_now(用来+4)
B:rs2 4 IRimm
IR和DR都是读出来的内存数据,C给地址保存到DR,B给数据写入C的地址。
步骤划分
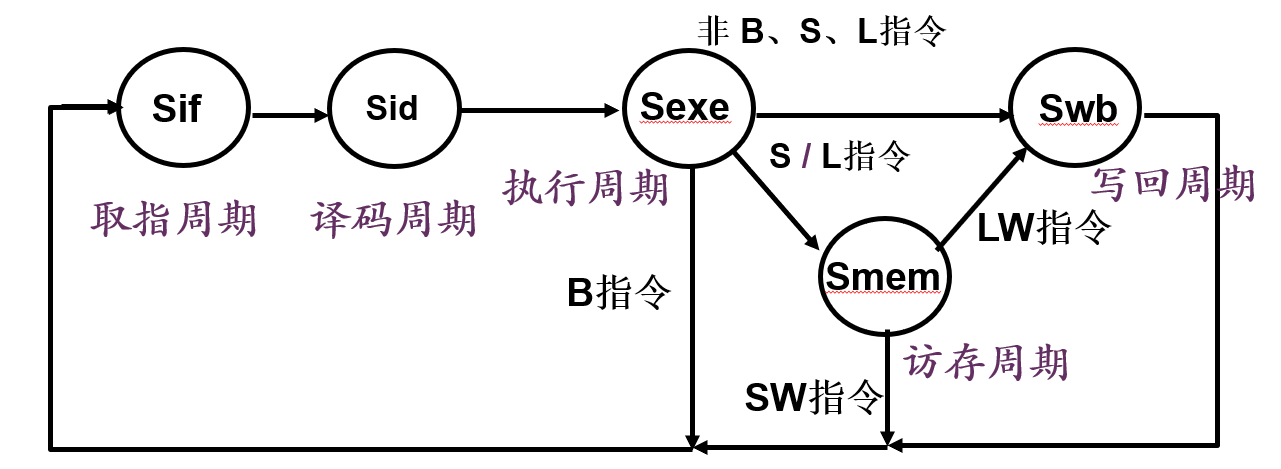
取指可1拍,之后:
B型指令:读寄存器堆(RF)、ALU运算(EXE),可2步完成,
R\J\U\I和S型指令:读寄存器堆(RF) 、ALU运算(EXE)和结果写回(WB), 可3步完成,
Load指令读内存指令:读寄存器堆(RF) 、ALU算地址(EXE)、读内存数据到DataR(MEM),把DdataR内容写入寄存器堆(RF), 可4步完成。
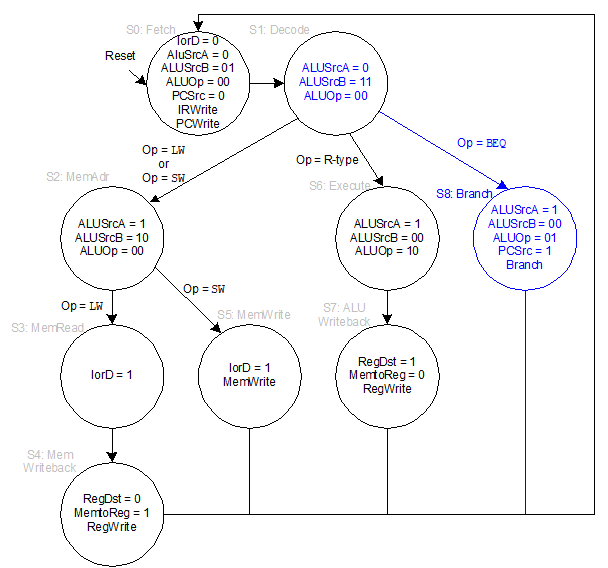
26 流水线cpu
连接图(1d链表)和时空图(xy表示时间-阶段)
最慢流水段限制时钟周期,必须是连续任务
装入时间第一个任务进入流水线到输出流水线
排空 最后一个任务进入到输出
部件功能级(浮点运算)、处理机级、处理机间级
吞吐率:ips? 加速比:与串行时的速度比
“每条指令至多需要5个周期”
27-28 流水hazards
结构冲突
硬件资源冲突——stallor增加资源
1 寄存器同时读写——2R1W独立端口OK or 双沿访问,下降沿写入 后半周期读出FPGA不可
2 内存冲突 IF和MEM——stallall or 区分i和d的内存 or 让mem的指令先走,插入mem气泡,stall住前面指令
数据冲突
数据依赖关系的冲突
RAW 写后读。后三条收到影响
后两条需要数据前传(exe已经可用,传给后两条的ID) or 插入两个bub。
后面第三条可以双边访问或者寄存器堆中特殊处理
数据旁路:给rs1 rs2的mux再加两个源头,来自aluy和dmload,其实是前传给了EXE
装入使用冲突 但不可MEM刚装入就前传给EXE,需要等待load。建议插入一个气泡nop。即先把mem放过去,在mem插入bub然后再…
建议汇编直接在load delay slot里面放一条无关指令——汇编器调换顺序,静态调度
或者硬件动态调整顺序,动态调度避免暂停。指令顺序发射——乱序执行——乱序流出。容易不精确的异常
条件 EXE和MEM的rd == ID的rs且不是zero
WAW 在 riscv不发生,只有wb才写所以…如果alu算完直接在MEM写,那就冲突
WAR riscv不发生,因为写远在读之后,后面的指令先写前面指令再读,不可能
控制冲突
分支、跳转类型指令改PC造成控制冲突——全局冲突
暂停流水:发现分支类就暂停后面指令进入,直到MEM产生正确pc,下一周期才IF
希望尽早判断是否转移and转移PC3
提前分支:在ID阶段加入加法器比较器完成转移地址计算,即把IF清空为nop然后下一阶段ID nop IF 跳转后的instr
分支预测:预测转移失败or成功,如果预测错误要消除影响。
BTB:分支目标缓冲,分支转移成功的指令地址和目标分支地址都保存起来,缓冲区以分支指令地址作为标志。在IF阶段,指令地址和保存标志比较,如果相同认为是分支指令且认为其转移成功。
相当于新的PC保存其下一条指令的地址,利用局部性
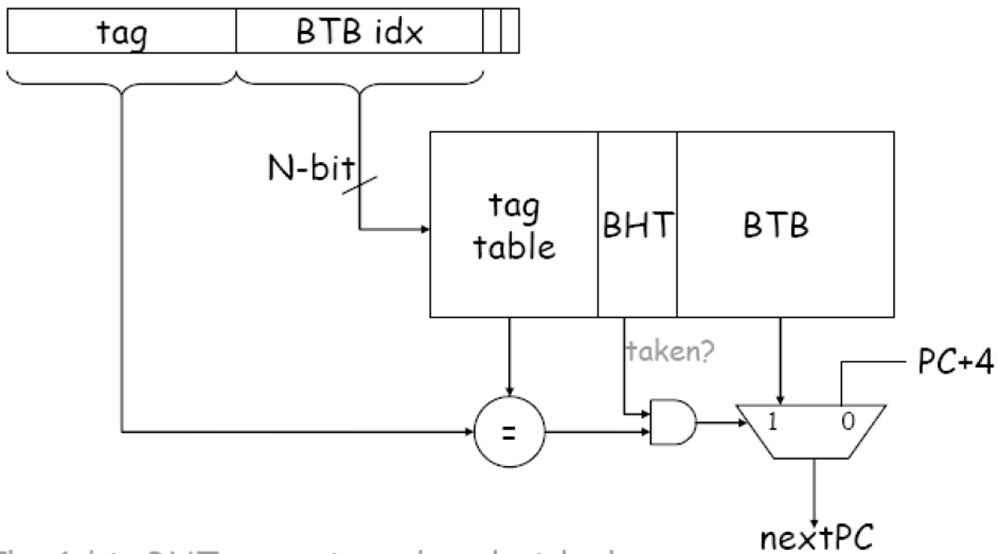
两位预测适用多重循环,连续两次错误改变预测方向
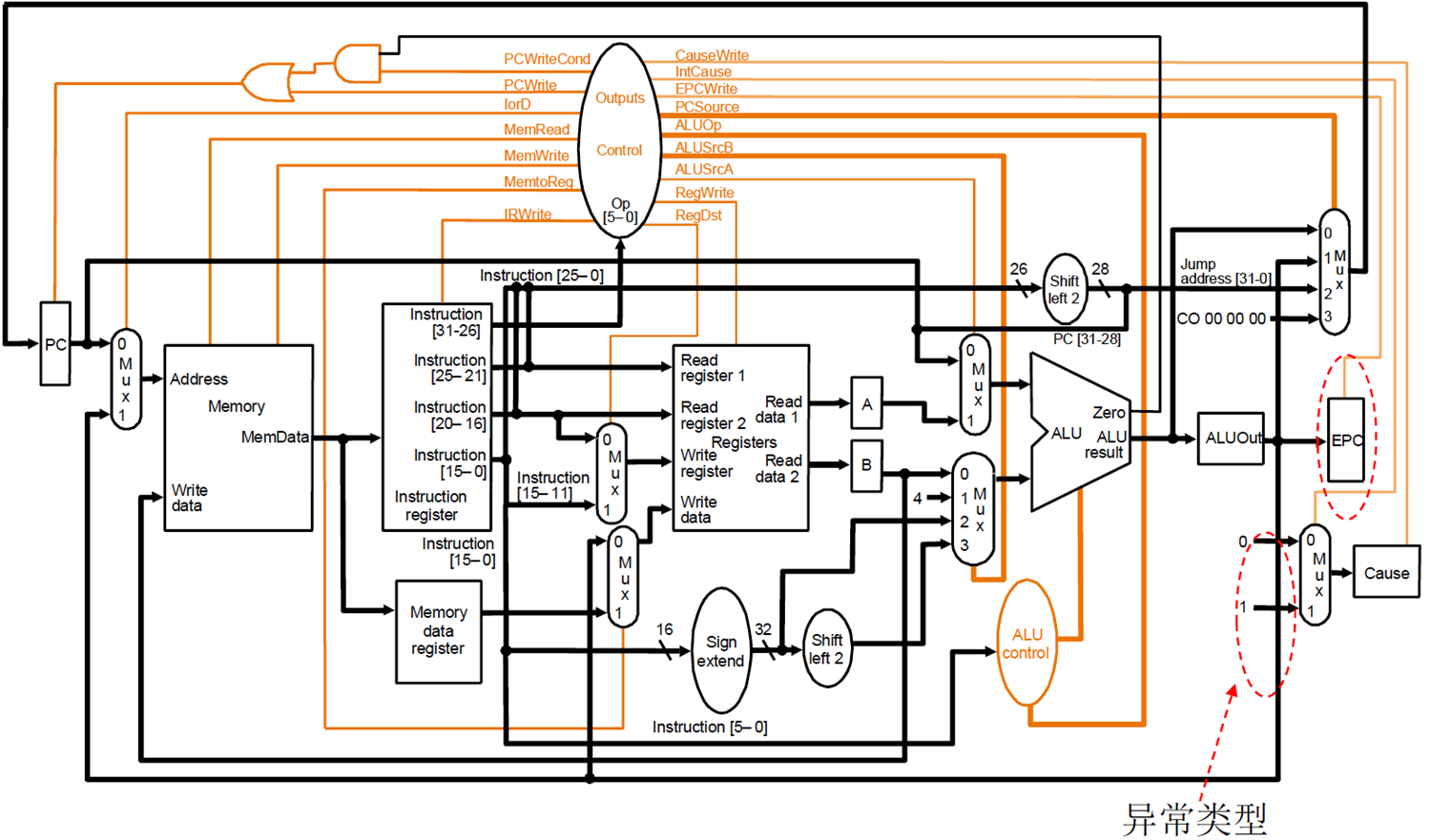
异常中断
cpu内部异常 外部中断
cpu对程序透明地检测和转移。保存现场、转到恢复程序、恢复现场
多周期可以增加一个检测异常是否发生的步骤。
流水线需要看是哪一步发生了异常
- 精确(RV):mepc保存发生异常地址,OS简单,流水复杂
- 非精确:mepc保存近似pc,os处理
28 expception MMU
M简单嵌入——MU安全嵌入——MUS操作系统
用CSRRW同时读写
机器模式最重要的特性是拦截和处理异常
异步中断,mcause最高位为1(一般是软件、计时器超时、外设),同步异常(包括环境调用 缺页等等)为0.mpp设置为u然后mret则从m到u,结束异常处理。
同步:ecall 进入高一层中断处理 ebreak故意触发断点异常
mepc 对于同步异常,mepc指向导致异常的指令;对于中断它指向中断处理后应该恢复执行的位置。
mtvec 异常跳转到的地址向量表。mode0表示跳base,mode1表示跳到base+4*mcause
mie 中断的使能 ,有的必须忽略 mip 正准备处理的中断
其中有 MSU e>s>t外部事件软件 E和P
只有U和S的pending可以地址写???向低优先级注入中断的手段。挂起中断的清除。
mtval trap value trap的附加信息比如出错地址,异常指令
mscratch 机器存放一个字数据
mstatus 机器状态:包括中断全局使能MIE,异常后的中断开关MPIE(保存中断前的旧值),MS响应中断特权级…
中断处理 设置mepc 根据mtvec设置pc 保存mcause和mtval mstatus保存mpie并mie置0.保存之前权限到mpp并权限改为M
抢占异常处理 处理中打断,转到更高优先级中断,需要保存m系寄存器到栈。在退出前,禁用中断,恢复寄存器
wfi 没有工作,低功耗待机等待中断。停止时钟ornop,适用于循环。
PMP物理内存保护 实现pmpaddr_x和pmpcfg,[i, i+1)的地址查找pmpi+1配置获取权限。M指定U访问的内存
Supervisor 不能用csr指令受到PMP限制,默认异常交给M但是M可以导向S。rv提供异常委托,选择把部分中断和同步异常交给S绕开M
mideleg和medeleg寄存器委托给s处理的中断、异常,每一位对应一种异常。sie和sip只有被委托的位才能使用。
页式虚拟内存
SV32 VA 10 10 12 PA 12 10 12 PTE 12 10 2 8 satp mode asid ppn22 在OS设置好页表后被启用
PTE低位:VRWX 用户可否U 所有地址空间有效G 访问过A 修改过D
satp.ppn, va.ppn0, 00 ==> pte0
pte0.ppn, va.ppn1, 00 ==> pte1
pte1.ppn, va.ppo ==> page entry
31 Dramlu
半导体存储器 mos寄生电容+触发器 属于ram
随机访问RAM 顺序访问磁带SAM 直接访问DAM随机+顺序,如磁盘
CAM关联访问,cache
需要:快、大、贱、可靠——层次储存
局部性 时间重复,空间重复,顺序上
一致性和包含性 不同层级的信息一致,外层包含内层
sram 不需刷新 触发器储存 同时送行列地址 热 IO共用管脚
dram 动态 需要刷新(漏电,补充电荷刷新。暂停读写集中刷新或者定时周期性分散刷新) 电容MOS存储 破坏性读出(需要马上写回叫做预充电延迟,影响频率)快速分页组织,行列地址两次给出,行地址可以锁存复用
两次操作 有个row buffer,所以hit row之后只需要col来读出
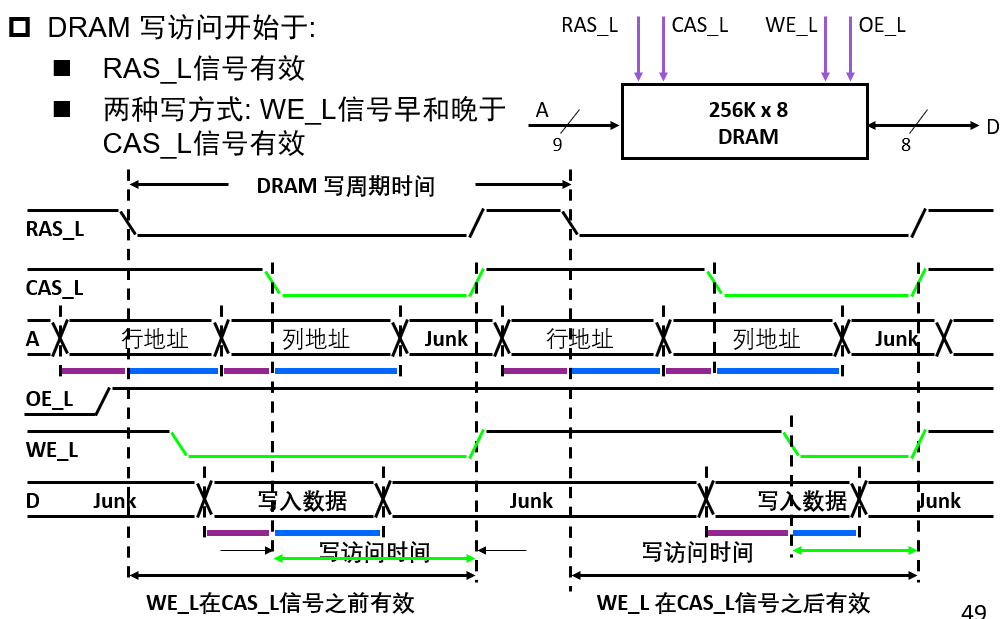
读写
读:地址;片选和读;保存内容
写:地址;片选和数据;写命令
Dram子系统组成 倒三角 channel DIMM RANK chip bank row/col——双通道,DIMM是一条分为前后两个rank01,rank里8chip,chip里面一堆层叠bank。bank大概是16krow 2kcol 每个unit1B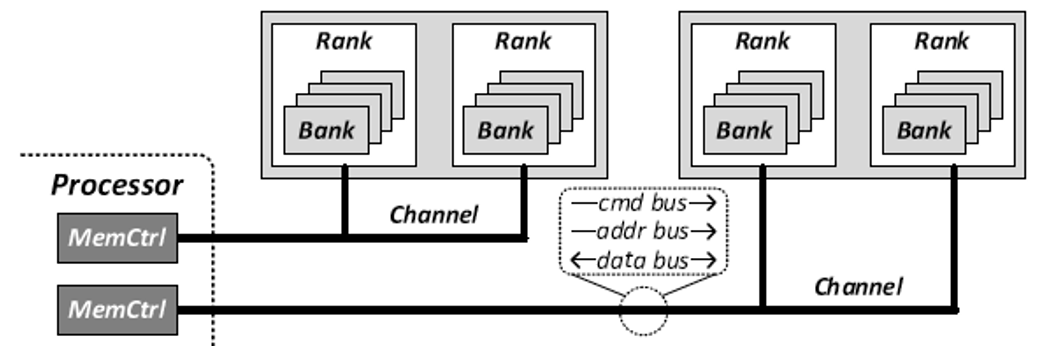
数据总线 clock*总线宽度就是数据吞吐能力 ddr带宽16B?100Mhz 200MT/s 1.6GBps
控制总线可以用不同的总线周期来区分部件,和操作性质,还有DMA周期等等
写时序
32 33 Sram&Cache
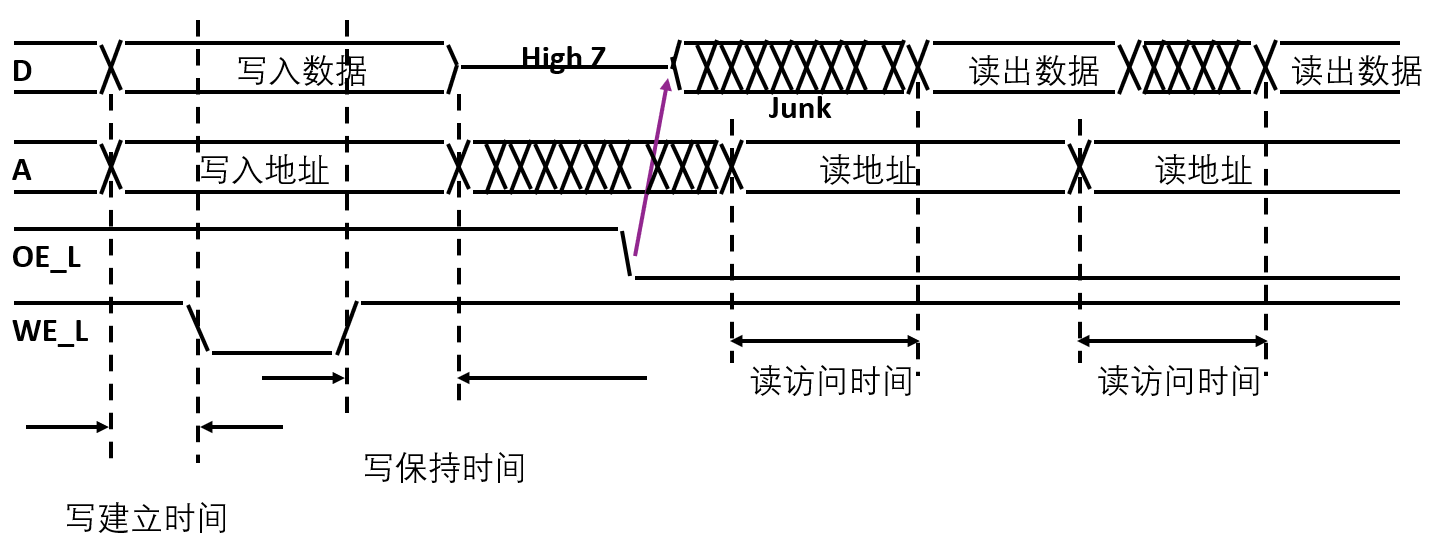
时间局部性:最近被访问的信息,空间:最近访问信息附近的信息,都装到cache里
Cache参数
line块 数据交换粒度单位 4~128B
hit 时间:访问高层次数据时间 1~4Cycle
miss 损失:替换高层数据块+交付cpu时间
命中率八成到99
容量1 256KB
映射方式
全相连(无序)
标志位是主存有2^m块就m位。所有表项都有单独的比较电路。即需要一个全长的tag,没有idx。
相当于主存中的一块可以映射到Cache的任何地方,即把全部地址作为索引,所有都需要比较器比较。最后选择器选择。
评价:灵活,命中率很高但是电路过于复杂
替换时:不确定换出哪块,需要判断
tag+line offset
直接映射——唯一对应位置
按indexO1的索引到,组内使用tag来比较器判断。
评价:每一块都有有直接的字块对应,方式直接,利用率低。标志位短,比较成本低,tag需要addr-cacheidx且仅比较一次。
但是利用率低,命中率低,效率低。
把主存地址中提取部分作为块号,部分为块内地址
n路组相连映射
主存中的一块映射到Cache中的N个位置。先索引组,然后里面找tag进行比较,如果相等则命中。组内直接映射
n个比较器和一个n选1数据选择器
替换时:不确定换出哪块,需要判断
n路多,命中率高冲突少,但是复杂,越来越接近全相连了
二路一半容量和直接映射的命中率差不多
一致性保证
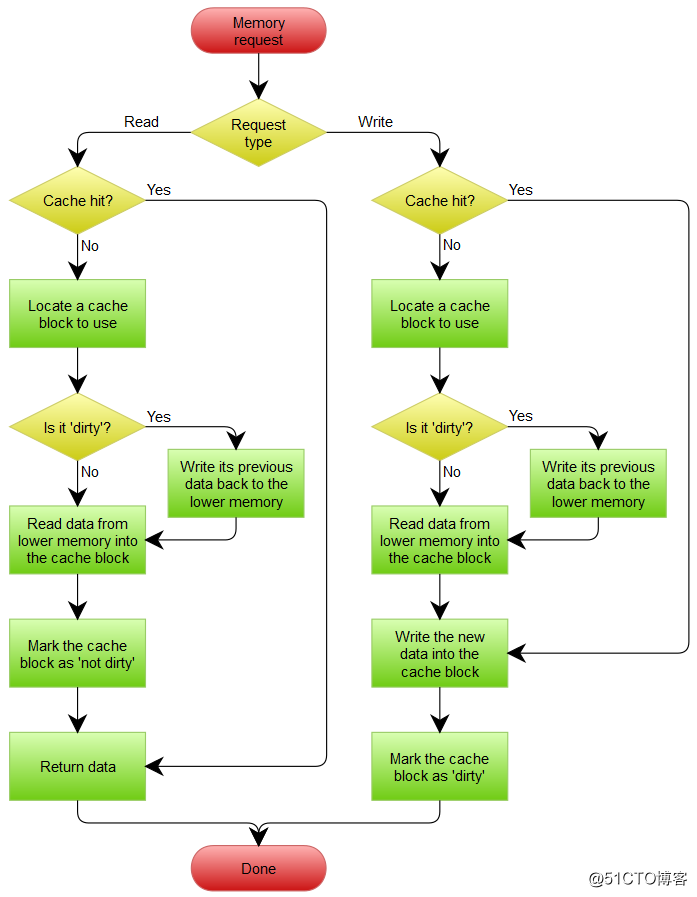
- Write Through写直达:cache命中后写mem和cache。不命中写mem时候可以同时allo cache
- 强一致性,低效
- Write Back 拖后写 只写cache,被替换时候dirty(主动被动,需要监听总线的操作)时才写给mem保存
- 适于多写
- 实现复杂但是效率高
miss原因
- 必然缺失——预取
- 无法避免
- 开机、切换进程、首次访问
- 容量缺失——扩容
- 活动数据集超过Cache
- 冲突缺失——增加路数or容量or更改策略
- 多个映射到一起,需要腾挪
- 某一个组块满了,其他组有空闲,就不叫容量
- 无效缺失
- cache数据不对,其他进程修改了主存,监听到并Valid=0
提升命中率
- 大块 可以更好利用空间局部性,但是装入慢miss惩罚太高。且块太少容易miss,有极值最优点。
- 块过大影响时间局部性
- 多级cache提高命中率;分成I和Dcache分别选择;
Cache接入
连入总线 简单 便宜 占用总线
单独连接cpu 提高总线效率和并发操作 成本高 结构复杂
一致性状态策略MESI
多个核心之间有本地cache,其他核cache和内存数据
修改:本地写
无效:远程写
共享:远程读 or 远程有副本的本地读
独占:远程无副本的本地读
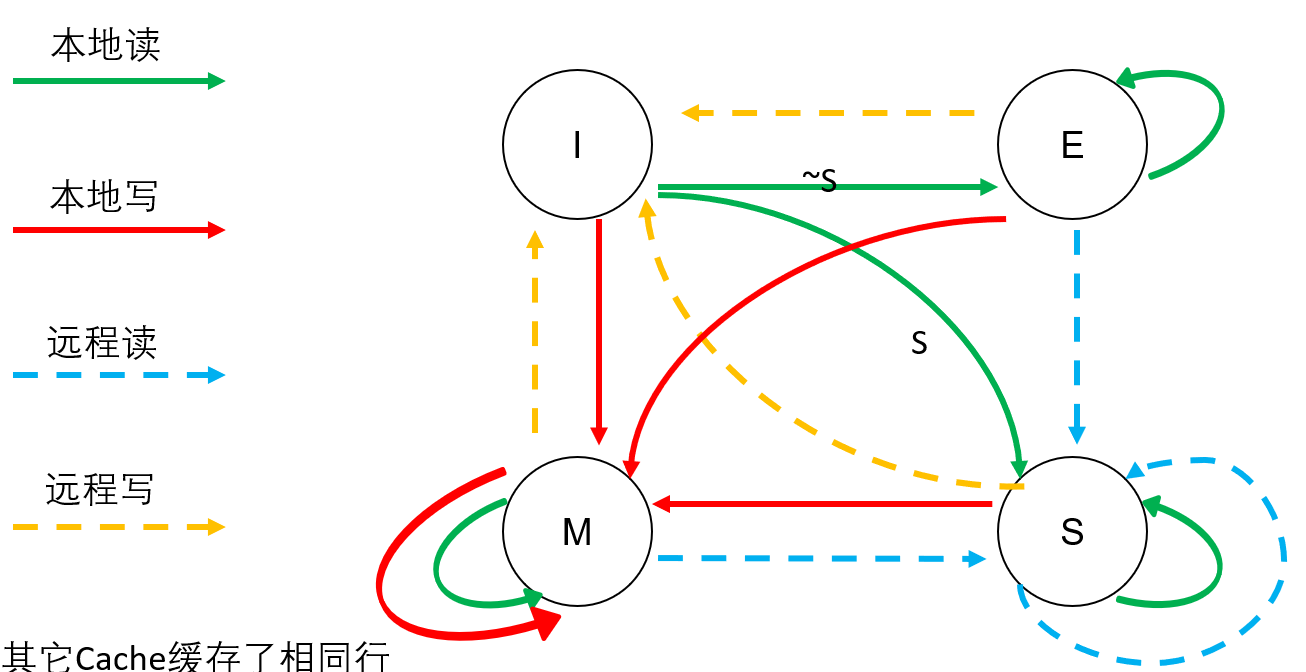
替换策略
FIFO 简单,满足时间局部
LRU 最近最少使用:复杂,满足程序局部性,命中率高
RAND 简单,命中率不低
34 VM
解决问题:程序数据量大于物理内存;多个程序共享;
共享和保护:多个进程可能使用相同的VP访问相同(共享库)或者不同的物理页。可以限制不同进程的权限。
页表大小的选择:层次页表|翻转页表,访问频繁所以要实现简单
页表可能给出内存or硬盘位置
0 null代表没有被分配
0 硬盘位置代表这部分的数据存在硬盘中,cpu选择空页或者牺牲页(被换出主存前如果被修改过,则写到硬盘中)然后从磁盘里把这部分拷贝到页面同时标注页表valid1
TLB
sfencevma 通知cpu页表可能已经被更改 rs1虚拟地址 rs2进程ASID
TLB缺失 暂停流水线,通知OS?,读页表,TLB更新,返回user,重新访问就hit了——多路组相连and扩容
缺页全流程 触发缺页异常,硬件设置好CSR后交由对应OShandler。(主存已满时,OS选择替换页,如果dirty则CPU请求把该页内容写入硬盘)CPU请求硬盘读入对应页到内存对应页,更新页表项。同时CPU硬件上更新对应TLB,返回到mepc地址,此时再次尝试时TLB已经命中。
读写硬盘过程:cpu唤醒IO硬件,硬盘通过IO触发完成中断。
页面大小选择
小页:减少内部碎片,需要更大页表
趋势:增大页面——RAM便宜内存大,内外存差别大,程序员需要大空间
页面替换:LRU,最多使用到最少使用排序。访问页帧移到表头,替换时替表尾部。替换非dirty
段式存储管理
VA: 段号(可以有两位表示优先级)+段内地址,每个段segment按逻辑关系分配长度,不定长,在段表中规定。
逻辑段共享,按照需求划分,页表方便管理。段表没有内部碎片,页表没有外部碎片
STE:段号 段长 段地址,段号和段内地址都有可能越界
段页式存储 先分段 再分页:段号 也号 页内偏移
35 外存|辅存
非易失性存储,粒度大,以数据块为单位
随机访问vs串行访问。各自or共用读写设备(顺序and直接)
磁记录方式 RZ归零正负脉冲10,中间0 NRZ一直正负脉冲 NRZ1见到1翻转
PM相调制中间上0下1
FM调频,1的中心翻转 0不翻转 位位间都翻转
MFM两个及以上0位周期起始翻转
磁盘
旋转托盘磁颗粒储存,移动读写头来访问。
相比软盘面积大 密度大 转速快 盘片可组合
访问过程 寻道(读写头移动8-20ms) 旋转寻找扇区(等待磁盘旋转到扇区) 数据传输(多个扇区)1kB扇区是最小访问单位——外磁道可以比内多一些扇区
时间 寻道+旋转+传输+控制延迟
额外开销大,尽量一次多传相邻扇区,或并行
小扇区:损坏代价;检错效率;灵活适应OS页面
访问磁盘过程 由缺页引起之后:
- OS选择一页换出,查看是否为脏页
- dirty页需要写回磁盘
- OS申请IO总线
- 获得批准后发送写命令给IO设备,传送写数据
- IO控制器根据命令握手协议,接受数据
- 根据地址移动到正确柱面、加载数据进buffer
- 寻道到正确磁道,旋转到扇区开始写入并不断计算校验码
- dirty页需要写回磁盘
- 继续申请读入所需页
- 申请总线
- 发送读命令和地址等
- IO接受,寻道,移动读写头
- 读数据并校验
- 磁盘申请总线
- 授权后送回数据
可用 能正常使用的几率——增加冗余如校验码
可靠 故障几率——改善环境,减少复杂
RAID
raid0 模拟虚拟磁盘划成带strip,每个strip有k扇区。相当于0123往下数数,适于大量数据请求,没有冗余和可靠性。
raid1 单纯四块主盘四块备份盘,写性能低,读性能两倍。成本高,可恢复。
raid2 4位半字节用海明码成7位字,124校验。然后磁头旋转同步写在七块盘上。需要多个控制器。严格同步
raid3 简化,对每个(半)字校验放在校验盘上,严格同步。用奇偶校验,能够修复单个磁盘bit1 bit2 b3 b4 Parity。瓶颈在校验盘,无论写谁都要算写校验盘
raid4 从bit到strip,生成异或的校验带。不需要同步,防止单盘崩溃但是字节纠错能力差。校验盘负载过重
raid5 分布校验带,控制和修复更复杂。从右到左分别当校验盘。
raid6 仍然分散校验带,但二维校验,3个数据2个校验位可以修复两个磁盘错。或者4-2异或斜向校验等等
SSD
不用动 安静 低功耗 高性能 抗震 擦除有限
固态电子存储芯片阵列——控制+存储(FLASH DRAM)
格雷码编码,内部也是个小计算机。
package-Die-Plane-Block-Page,最小读写单位。读写在4k-16k us延迟 擦除可以到block ms延迟
FTL层负责翻译地址,维护磨损均衡。写入同一地址不会在原来的page,跨很多。原来invalid,写入前擦除。
垃圾收集:把die block中有用的数据拷出来,然后整体翻新成free
41 IO
程序直接控制 cpu主动去轮询查
uart串口,在程序里通过特定指令(mmio或专用)来轮询状态并等待——接受or发送——处理
低成本 低效率 cpu资源阻塞占用
适用于早期计算机的中高速设备
程序中断 设备自己报告
完整过程
- 外部设备中断请求:设置中断触发器。每个中断源有1个中断触发器,也对应1个中断屏蔽触发器
- 中断响应:
- 条件:允许+当前指令结束(对多周期);优先级满足
- 过程:关闭pending中断;硬件的中断隐含指令,相当于在每个WB后看看有无中断,保存断点
- 根据中断源转到软件中断handler
- 关中断,保存现场上下文,各种regs,转handler
- 开中断;运行对应中断处理;关中断;
- 恢复断点现场
- 开中断;返回断点
可能分别有响应优先级和服务优先级。即响应中断的优先级低但是服务进行的时候屏蔽很多中断,不可以被打断
中断接口硬件实现
- 中断请求和屏蔽寄存器
- 优先级排队线路
- 数据缓冲寄存器
- 中断控制和工作状态逻辑
- 设备选择器
- 中断向量表:服务程序的入口地址
相关概念
- 中断触发器和状态寄存器
- 中断优先级——响应顺序
- 禁止和屏蔽(允许触发器EIDI 选择封锁)
评价和适用
提高效率,可以同时管理多个设备;传输速度不高量不大;对CPU干扰大。因为数据都需要cpu经手传输,比如什么中断服务程序。
硬件故障;cpu和外设并行工作;实时处理;app和os;多处理机的机间联系;多道和分时
怎么能不让cpu来做?尤其在页式交换?
DMA直接存储访问
IO设备和主存的直接数据通路,专设硬件。传输过程DMA自己控制,需要主存支持 成组传送(burst)。开始和结束时需要程序or中断来预处理和后处理
仍然是通过bus传送,怎么协调?工作方式:独占总线(等我传完)or周期窃取(每次传输后释放,一起竞争总线)
使用与连续地址的大数据量传输,解放CPU
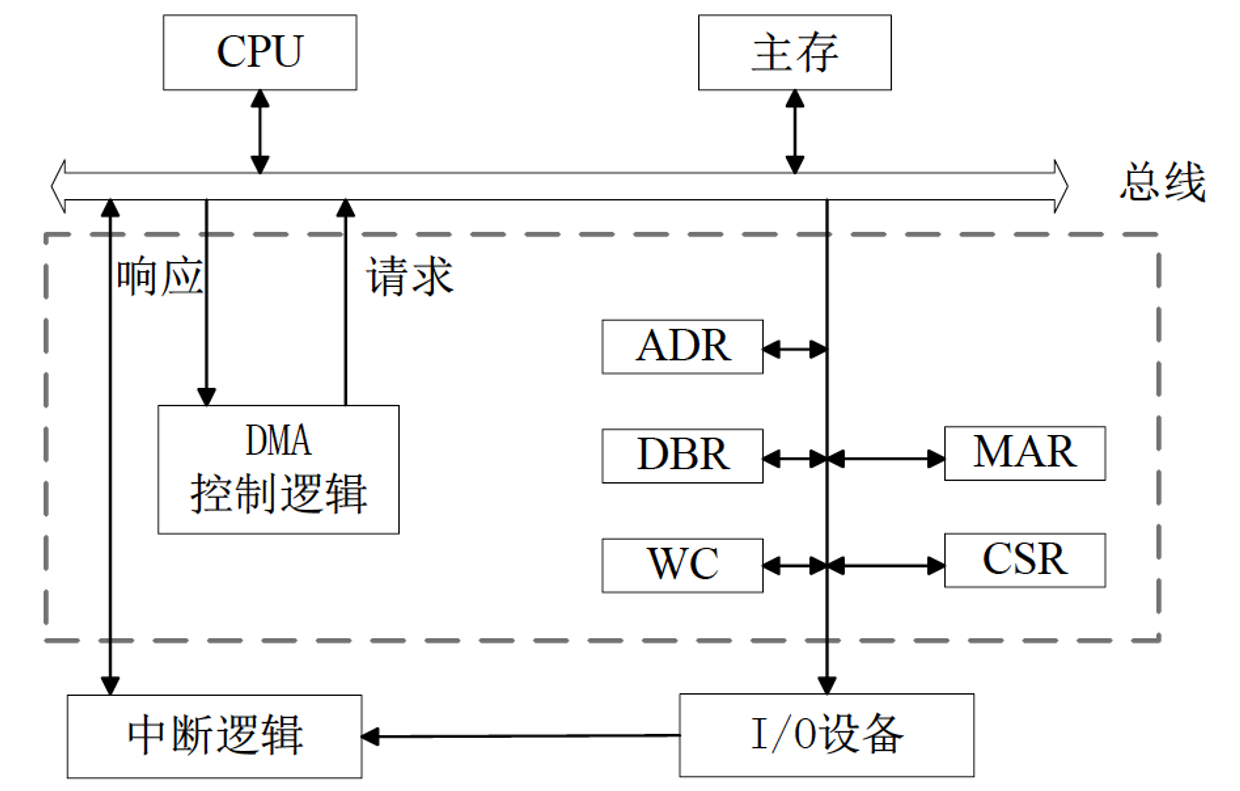
io可能通过中断向cpu发出请求表示数据准备好,cpu告诉dma任务信息(硬盘、地址adr、主存地址mar、数据量word count,dbr数据缓冲,csr状态寄存器等等)。
dma卡自己请求总线完成任务,然后告诉cpu传输完(申请中断),cpu再去处理这些数据。
工作过程
CPU预处理:启动并给任务信息
将内存起始地址,设备地址,数据个数等送到DMA启动设备
数据传送
cpu继续执行主程序,dma控制同时完成数据传送
- 申请总线直到允许,地址送到总线,数据送IO;主存地址+1,WC内容-1.
- 传完了
中断服务程序进行DMA结束处理
评价
DMA需要连续的物理地址,但是cpu拿的是VA,其物理地址不一定连续。cpu的VA需要DMA虚实转换,需要访问tlb,产生冲突。
Cache一致性、包含性?层次问题:
- 主存数据并不一定最新,可能在cache中
- 主存更新后的cache失效,如果还要管cache性能低
DMA与设备是一对一的,多设备需要多个DMA,同时工作可能会冲突。
对CPU打扰适中,初始化和周期挪用,无法适用大量高速设备
通道控制方式——1个DMA集成管理多个设备
通道命令IO处理机,有自己的命令,一对多,适应不同种类的和不同速度,其实是专用cpu。
指定连入外设,操作外设;传入外设IO的位置以及主存缓冲区地址;控制外设和主存交换数据;检查外设状态;
字节多路通道
简单共享、分时处理,低中速字符设备
选择通道
选择外设独占整个通道,成组传输数据块,效率高的快速设备
数组多路通道
结合前两种。复杂控制但高效
外围处理机
通道型处理机:共享内存
外围处理机:独立IO,帮助大型机专心计算
总评价
性能、可扩展、可适应(设备有无、故障)
考虑驱动、依赖等等,尽量使用抽象统一标准,虚拟化管理
42 BUS
概念
cpu和其他部分的接口
性能:延迟、吞吐量、设备和系统的连接关系、层次存储、OS

好处
复杂外设:使用统一总线标准,便于扩展和兼容
降低成本,可以多个设备共享
设计简单
不足
- 总线带宽限制吞吐量
- 最高速度决定因素:
- 总线长度
- 负载设备数
- 负载设备特性:延迟差异、数据传输速率差异
单总线设计:主板总线
处理器和mem和io都连接,简单低成本,但是速度太慢,成为系统瓶颈
双总线:处理器主存总线和IO总线
麦金塔II 两极总线,设备并不直接连接到处理器主存总线上,通过总线适配器引出单独的IO总线。
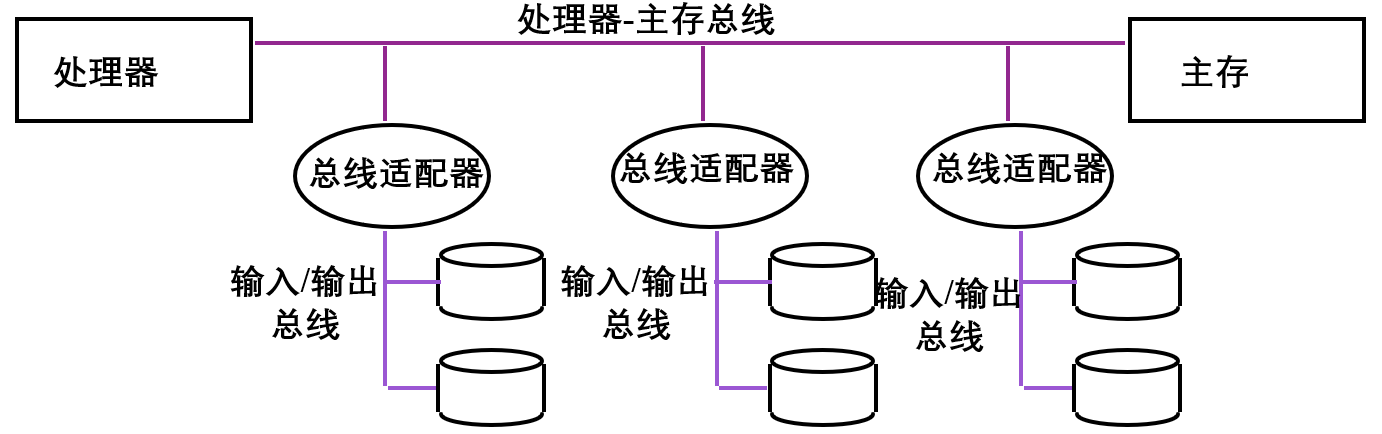
三总线:处理器主存、主板总线、IO总线
三级总线,mem-PCI-usb、ethernet、disk
大大减少处理器主存总线负载,
现代PC采用北桥接入高速设备,南桥接入低速设备。但是现在北桥基本都被继承进cpu直接接高速设备
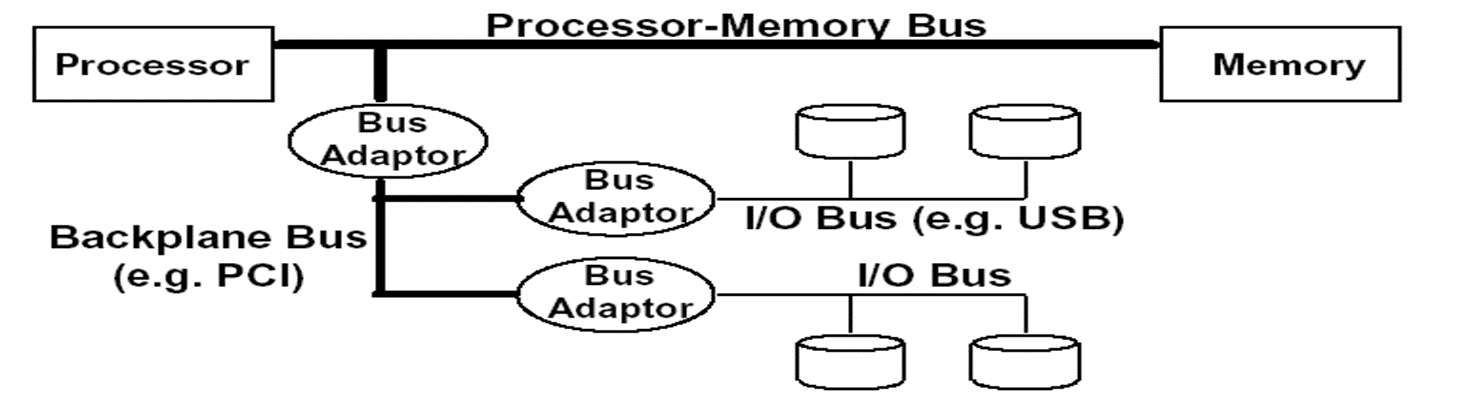
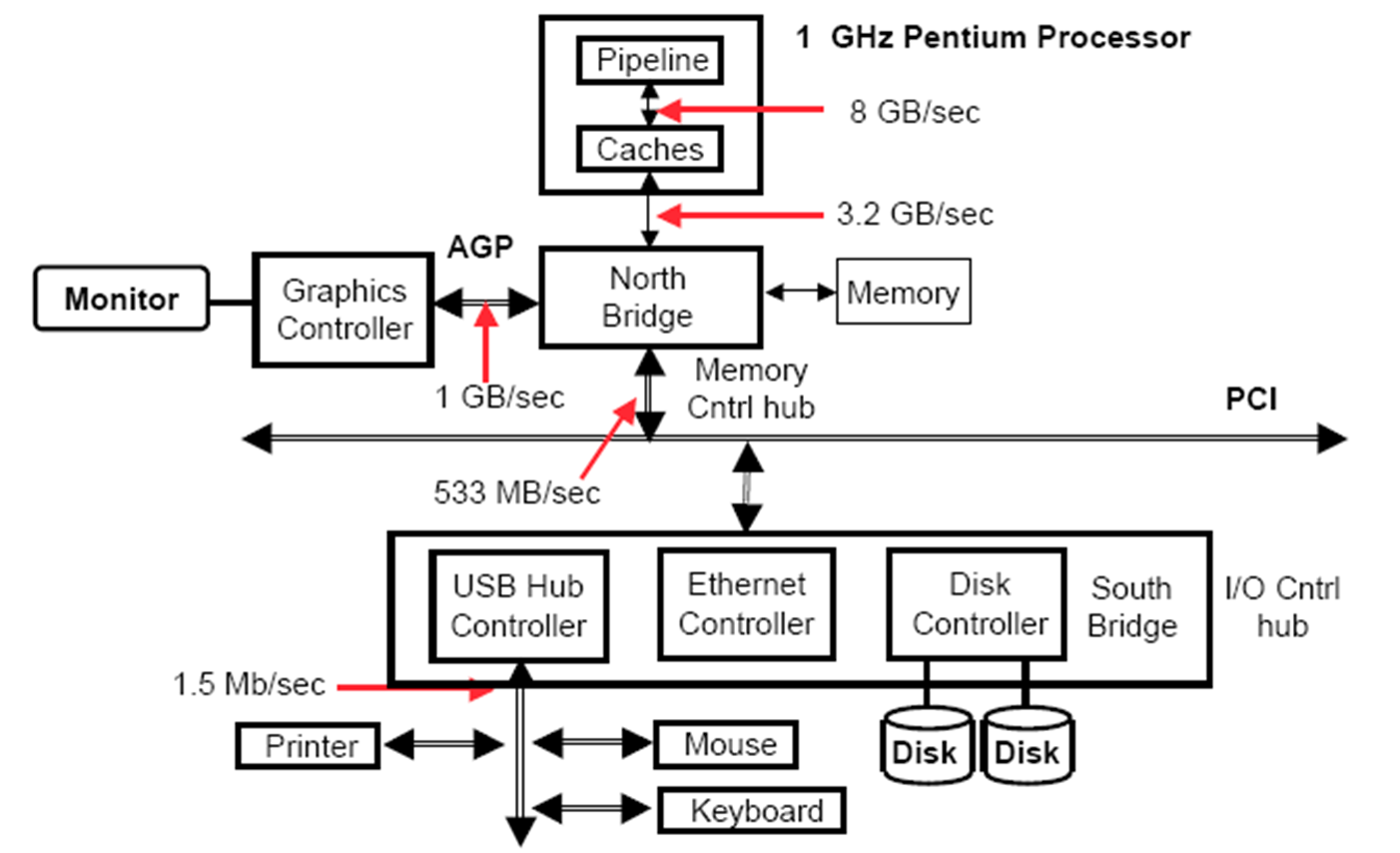
总线类型
处理器主存,专用
短、高速、专用于主存直连处理器、针对cache块优化设计
IO 行业标准
长慢,适应性好、通过桥or主板总线连接主存总线
主板总线 高速设备
允许处理器、主存和IO设备互连,所有组件都连接在这条总线上
有价格优势?
总线构成
控制线:总线请求和数据接受信号;指明数据线的信息类型
数据线:传送信息,数据和地址,复杂命令
总线标准
非常多,抽象设计,影响性价比可靠性。需要统一、可扩展、兼容、协调控制
PCI;EISA;SCSI;USB;Bluetooth…
总线层次结构 事务协议;时序信号规范;导线;电气信号规范;接口物理机械特性;
总线概念
主设备 控制总线,发起总线事务(发起命令和地址+数据传输)
从设备 响应请求
通信协议 定义总线传输中的时间顺序和时序要求
异步同步
控制信号作为总控,适应不同速度,距离长,需要握手
共同时钟在控制线里,逻辑简单高速,但所有设备需要按这个时钟工作;总线需要够短
同步协议
最理想 完全同步,所有设备速度一样。req grant 上升沿关闭req G后直接给addr和cmd,很快得到data
典型同步 给出cmd和addr后,wait信号直到数据准备好,wait为0(wb协议)根据时钟信号得有效数据。即从设备指示什么时候开始传送…
同步定时 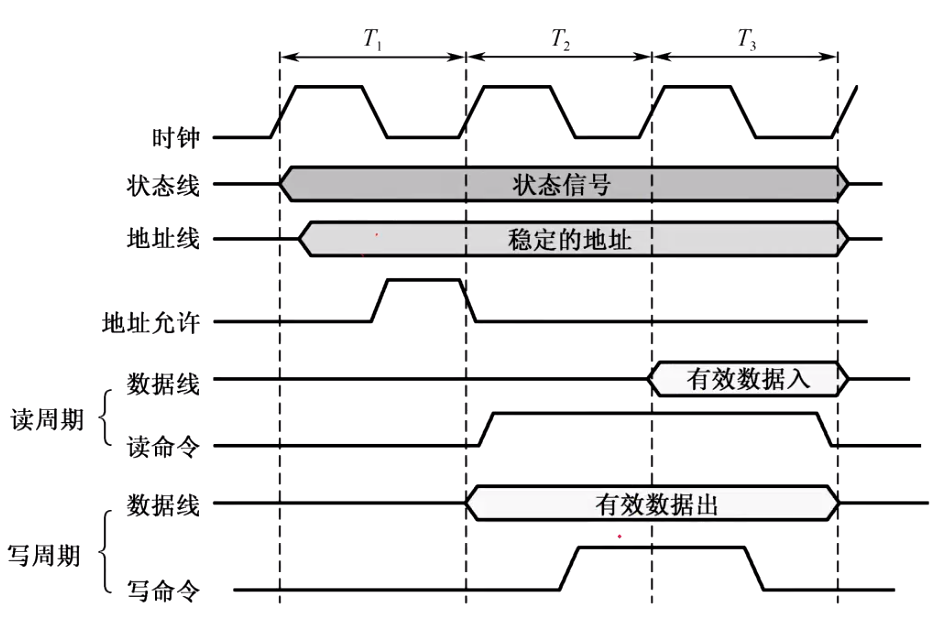
异步协议
沟通通过握手信号解决,主要是ack和rdy。
外设读取主存的过程:
外设req
主存读到地址发出ack
外设释放req和数据
主存关闭ack
主存把数据上bus并datardy
外设读到之后ack
主存关闭rdy
外设关闭ack
总线仲裁
要求
主设备请求——授权并使用——完成后通知仲裁器释放请求
优先级和公平性
古典简单
处理器是唯一主设备,控制所有请求,被卷入每一个总线事务。
集中仲裁——菊链仲裁
统一bus arbiter,接入各个设备release request的线或。并不知道谁在req,只要没在占用就grant通过。有绝对的优先级。按照优先级级联grant信号。
每个设备的req和release线或在一起,arbiter不区分。grant授权按照高到低串联一起,高优先级可以截断授权。
无占用就发放grant
不公平,低优先级用不到,授权信号逐级限制速度
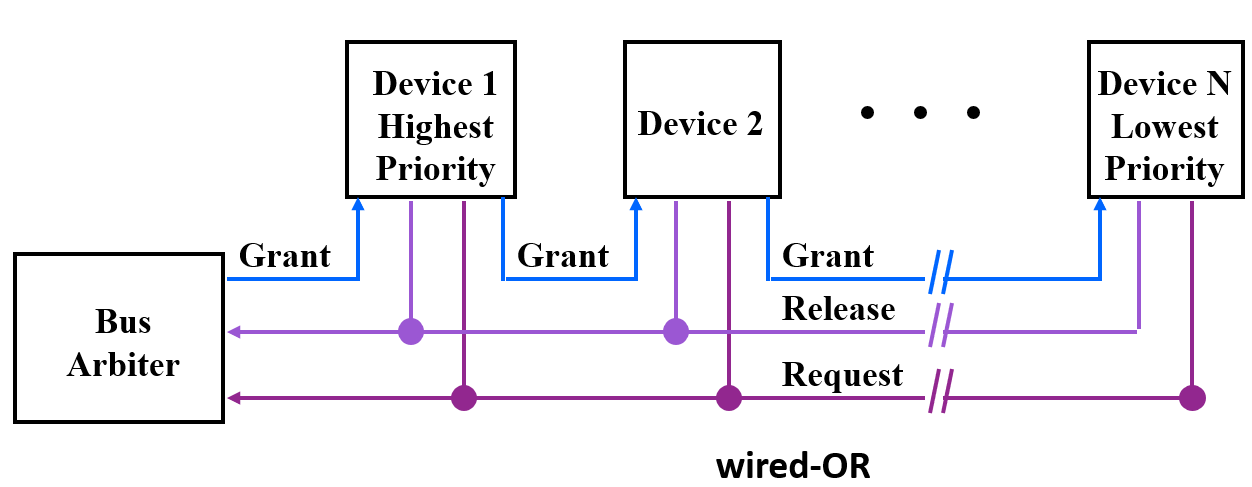
集中仲裁——集中平行
集中接入所有设备的请求和授权,用于所有处理器主存总线和高速输入输出线
分布仲裁——自我选择、碰撞检测
把自己的标识符放在总线上
增加总线带宽
增加总线(数据)宽度
增加每个周期的传送数据量,成本高
分开设置数据和地址总线
同时传送地址、数据,成本高
采用成组传送
每个事务传多个data单元,一开始传一个地址,传完所有数据再释放。
复杂度高,延长后续总线请求的等待时间
相当于一个地址之后一组数据而不是一个du
多Master总线提高事务数量
- 当前事务中仲裁下一事务(仲裁重叠,提前仲裁)
- 总线占用:没有其他主设备,自己一直占完成多个事务
- 地址、数据传送重叠
PCI总线
外部组件互联总线,33MHz-133MB|66-528,正边沿采样
重叠集中平行仲裁Req#和Gnt#
32位地址和数据线互用AD,分为init和tar

frame有效传输信号,地址段在frame开始有效,在授权后开启。第一周期主设备cmd和addr,两个设备准备好对应各自的rdy。均rdy后上升沿开始传送,结束传送时关闭frame
devsel#表示target设备已收到命令,可以响应,TRDY接受
T4读到第一个数据,可以改变CBE#的值。
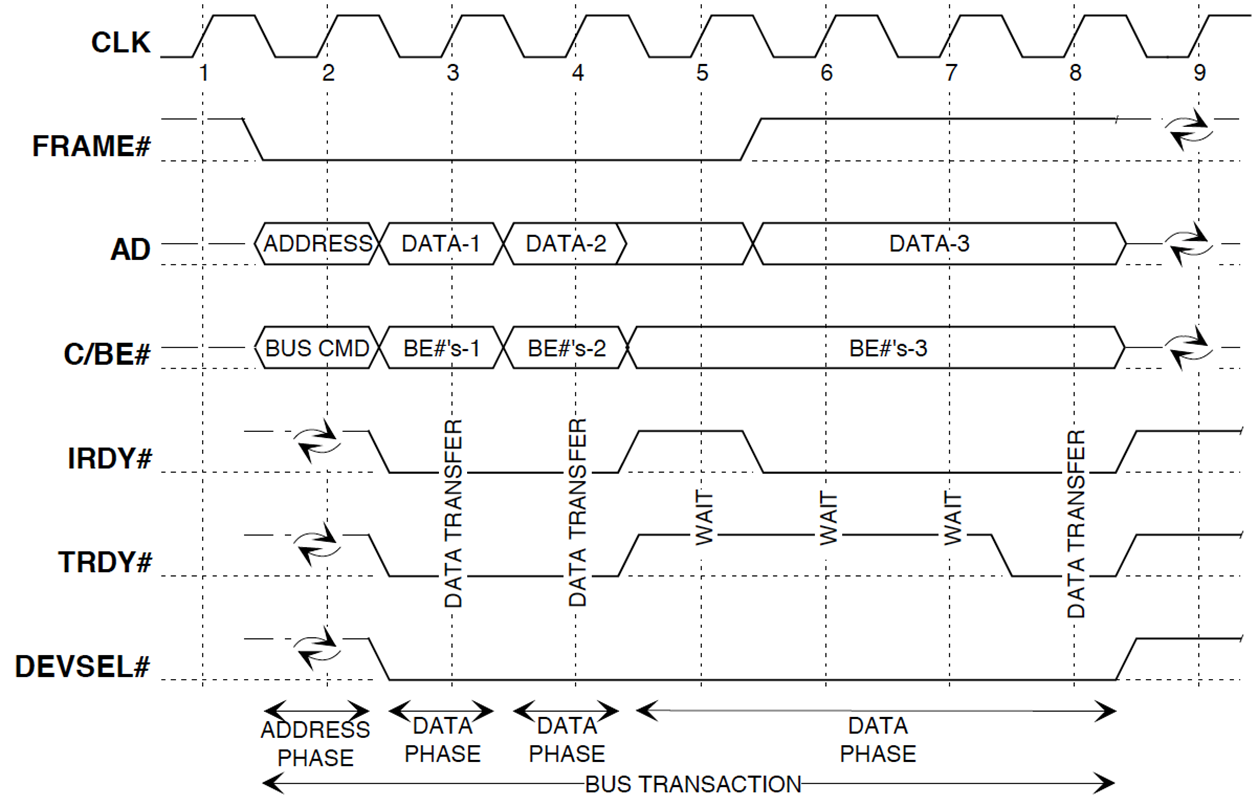
优化?
- 类似risc,并行仲裁和传输数据
- 为上一个主设备保留授权直到其他init
- 授权设备不需要再次申请仲裁
- 仲裁时长) 通过rdy延长传输流,tar也可以通过stop abort retry等信号终止,主设备通过FRAME# 仲裁器通过GNT
- 等对慢速设备,请求后暂时释放总线
PCI其他问题
中断、cache一致性(IO multicore)、加锁(分时操作)、可配置地址空间
发展趋势
逻辑上是总线,物理上是交换,采用点到点标准
DMA 独占总线:发cpu信号,控制器请求总线并一次性传输,再次通知cpu并释放总线
周期窃取:DMA优先级更高)有dma请求时IO设备随时挪用几个周期来一点点传,
交替访内:cpu周期专门分开,dma和cpu分别访问内存
43 接口和外设
接口功能 总线和外部设备的连接
识别和选定设备,规定地址码编号;
控制和通信机制;
数据缓冲;
特别需求如屏蔽差异
通用可编程接口电路 内部:识别电路、数据缓冲寄存器;控制、状态寄存器;中断电路;其他
串行接口8251A
内(同步符)外(硬件同步信号)同步异步(起始停止位、波特率)均可 5-8bits/word
异步时支持停止位、假启动(0不够长)、全双工独立线、双缓冲发射接受、检错。
空闲保持高电平;波特率因子即传送一个二进制位需要多少个时钟
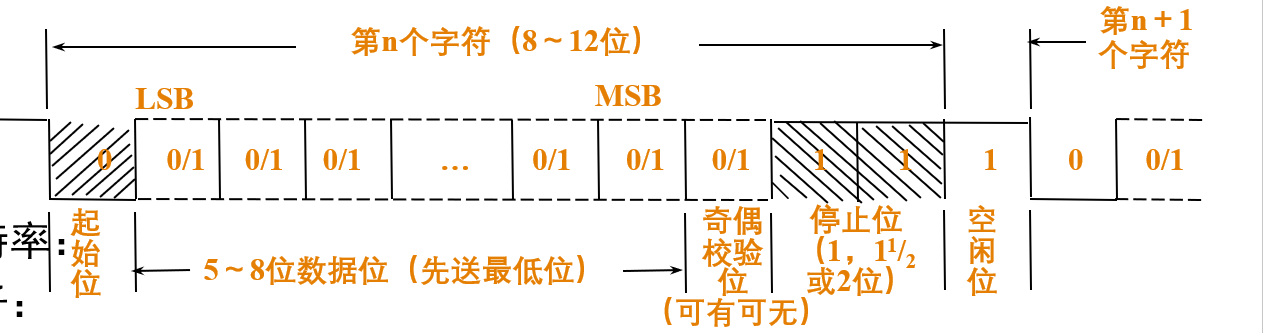
rst后根据8bit的方式控制字来实现编程,确定工作模式
命令字 正式开始工作的8bit
状态字 实时表示状态的8个bit
USB
最多127设备,实时,热插拔,同步
根hub定时查询接口,如果有接入则分配地址。设备上有rom保存参数,由os中驱动管理。
只有一个master,轮询,低速
帧类型:控制、SOF包时间同步、块传送、中断;F1读命令addr;F2设备返回data SYN PID payload checksum;ack确认;F3往设备写数据
键盘 按下为0,对应编码,中断工作
显示器 高速设备,真彩色需要3B,专用接口
打印机 激光照射硒鼓放电,不能吸墨粉为空白。慢速总线,并行接口